











情報がシステム内でどのように移動するかを理解することは、堅牢なソフトウェアおよび効率的なビジネスプロセスを構築するために不可欠です。データフローダイアグラム(DFD)は、この移動を視覚的に表現します。外部の情報源から内部のプロセスへとデータが流れることをマッピングし、データがどこに保存され、どのように変換されるかを示します。しかし、単一の図で現代のシステムの複雑さをすべて捉えることはめったにありません。ここに、レベル0、レベル1、レベル2のDFDの階層構造が不可欠となるのです。
適切なタイミングに適切な詳細度を選択することで、要件定義やシステム設計の過程での混乱を防げます。このガイドでは、各レベルにおける具体的な用途、構成要素、ルールについて解説します。プロセスの分解をいつ止めるべきか、およびドキュメント全体に一貫性を保つ方法について検討します。
🔍 データフローダイアグラムとは何か?
データフローダイアグラムとは、情報システム内を流れているデータの流れを図式化したものである。フローチャートとは異なり、フローチャートは制御の流れや論理的判断に注目するが、DFDはデータの移動に注目する。これらはステークホルダーが入力がどのように出力に変換されるかを視覚化するのを助ける。
- プロセス:データを変換するアクション。
- データストア:後で使用するために一時的にデータが保管される場所。
- 外部エントリ:システム境界外の情報源または目的地。
- データフロー:これらの構成要素間を移動するデータ。
システムを特定のレベルに分解することで、分析者は複雑さを管理できる。最初の図にすべての取引の詳細を示す必要はない。代わりに、広い視点から始め、必要に応じて段階的に詳細を絞り込んでいく。
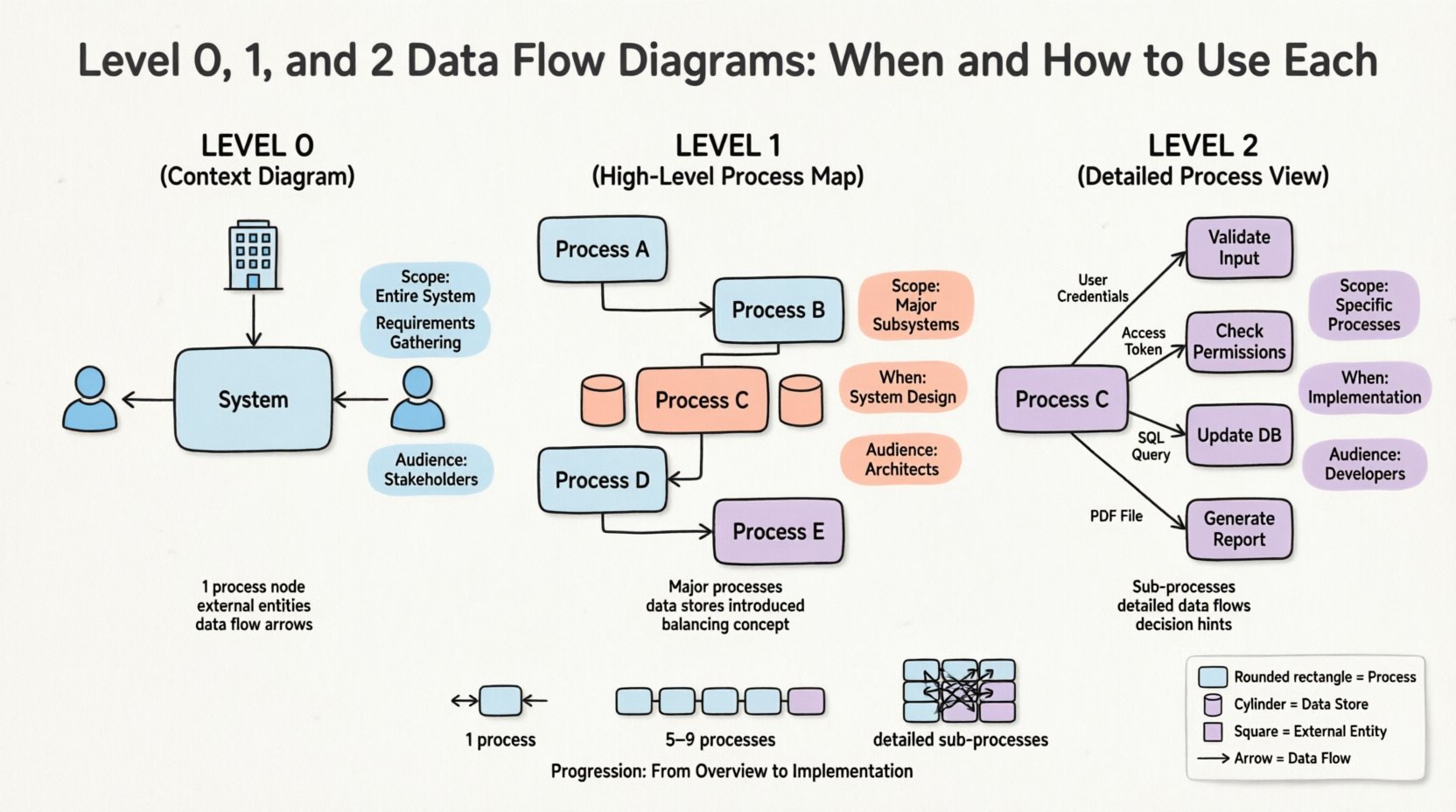
🌍 レベル0:コンテキスト図 🌍
レベル0のDFDはしばしばコンテキスト図と呼ばれる。これは、システム全体を単一のプロセスとして表現する。この高レベルの視点により、システムとその環境との境界が明確にされる。
🎯 レベル0を使うべきタイミング
- 要件定義:ステークホルダーと範囲を確認するために、早期に使用する。
- プロジェクト開始時:新規チームメンバーに迅速な概要を提供する。
- システム境界の定義:システム内部と外部の区別を明確に定義する。
⚙️ 主な構成要素
- 1つのプロセスノード:システム全体は、1つの円または角が丸い長方形で表される。通常、システム名(例:「注文処理システム」)でラベル付けされる。
- 外部エントリ:これらは、あなたのシステムとやり取りする人々、組織、または他のシステムである。例として、「顧客」、「決済ゲートウェイ」、「倉庫管理システム」などがある。
- 注意:内部部署が同じシステム範囲に含まれている場合は、外部エントリとして含めないでください。
- データフロー: エンティティと中央プロセスの間の入力および出力を示す矢印。
📝 例題シナリオ
図書館管理システムを検討してください。レベル0の図は中央の「図書館システム」プロセスを示します。外部エンティティには「図書館員」、「会員」、および「書籍仕入れ業者」が含まれます。データフローには、業者からの「新書籍リクエスト」と、会員からの「書籍貸出」が含まれます。
このレベルは次の質問に答えます:「システムとは何か、誰がそれに話しかけているのか?」
🔄 レベル1:ハイレベルプロセスマップ 🔄
レベル1のDFDは、レベル0の単一プロセスをその主要なサブプロセスに展開します。詳細な細部にこだわることなく、システムの内部構造を明らかにします。これは、ハイレベルなアーキテクチャ議論において最も重要な図であることが多いです。
🎯 レベル1を使用するタイミング
- システム設計フェーズ:開発者は主要モジュールを把握する必要があります。
- 機能計画:プロダクトマネージャーは、これを使って明確な機能領域を特定します。
- インターフェース定義:データがシステムに入り出し、APIを定義するための場所を特定するのに役立ちます。
⚙️ 主要な構成要素
- 主要プロセス:単一のレベル0プロセスを5~9の明確なプロセスに分解します。もしそれ以上ある場合は、さらにグループ化を検討してください。
- データストア:レベル1では、通常、データストア(データベース、ファイル、テーブル)を導入します。これにより、情報がどこに永続化されるかが示されます。
- 整合性:レベル0でシステムに入出するすべてのデータフローは、レベル1にも現れる必要があります。これを「バランス調整.
📝 例題シナリオ
図書館システムを引き続き検討すると、レベル1の図は「図書館システム」を「会員登録」、「書籍貸出」、「罰金処理」、「在庫管理」に分割します。データストアには「会員データベース」や「書籍カタログ」などが含まれる可能性があります。レベル0の「書籍貸出」フローは、レベル1で「会員データベース」と「書籍カタログ」とのやり取りを行うフローに分割されます。
このレベルは次の質問に答えます:「主要な機能は何か、データはどこに保存されるのか?」
🔬 レベル2:詳細プロセスビュー 🔬
レベル2のDFDは、レベル1で特定された特定のプロセスにさらに深く掘り込みます。単一のレベル1プロセスは完全に理解しづらいほど複雑な場合があるため、さらに分解されます。すべてのプロセスにレベル2の図が必要なわけではなく、詳細な仕様が必要なプロセスのみに限られます。
🎯 レベル2を使用するタイミング
- 詳細仕様:開発者向けの技術要件を記述する際に使用する。
- 複雑な論理:複数の判断ポイントや計算を含むプロセス。
- レガシーシステムの近代化:既存の複雑なワークフローを新しいシステムにマッピングする。
⚙️ 主な構成要素
- サブプロセス: レベル1のプロセスの分解。たとえば、「本の貸出」は「会員の有効性確認」、「在庫情報の更新」、「領収書の発行」に分かれる。
- 見づらさを避けるため、サブプロセスの数を制限する。
- 入出力の詳細: これらのサブプロセス間で渡されるデータ要素を正確に示す。
- 制御論理: DFDはコードのような論理を示さないが、レベル2ではしばしば判断ポイントが示唆される(例:「会員が有効なら続行」)。
📝 例題シナリオ
図書館の例では、レベル1の「罰金処理」プロセスが分解される。たとえば「延滞日数の計算」、「料金率の適用」、「口座残高の更新」などが示される。このレベルでは、罰金計算の論理が明確であり、ビジネスルールと整合していることを保証する。
このレベルは次の質問に答える:「この特定の機能は、実際にどのように動作するのか?」
📊 DFDレベルの比較
| 機能 | レベル0(コンテキスト) | レベル1(概要) | レベル2(詳細) |
|---|---|---|---|
| 範囲 | 全体システム | 主要サブシステム | 特定のプロセス |
| プロセス数 | 1 | 5~9 | 変数(詳細調査) |
| データストア | なし | 主要なストア | 詳細なストレージ |
| 対象者 | 関係者、経営陣 | アーキテクト、マネージャー | 開発者、アナリスト |
| タイミング | 要件定義フェーズ | 設計フェーズ | 実装フェーズ |
| 焦点 | 境界 | 機能性 | 論理とデータ |
🛠️ DFDモデリングのベストプラクティス
正確な図を描くには、自制心が必要です。特定のルールに従うことで、ドキュメントがプロジェクトライフサイクル全体を通じて有用なまま保たれます。
1. バランスを保つ
プロセスをレベル0からレベル1に分解する際、入力と出力は一致している必要があります。レベル0で「ユーザーのログイン要求」がシステムに入力されている場合、レベル1では同じデータが「認証プロセス」に入力されていることを示さなければなりません。データが突然消えたり、どこからともなく現れたりする場合は、図は無効です。
2. 名前付けのルール
- プロセス:動詞+名詞の構造を使用する(例:「注文を検証する」、ではなく「注文の検証」)。これにより、行動の重要性が強調される。
- データフロー:名詞句を使用する(例:「顧客データ」、「請求書」)。
- エンティティ:単数名詞を使用する(例:「顧客」、ではなく「顧客たち」)。
3. データスパゲッティを避ける
データフローが互いに過度に交差するように描かないでください。図が線の網の目のように複雑になると、おそらく複雑すぎるのです。レベル1のプロセスを別々の図に分割することを検討してください。
4. ファンクション間の直接通信禁止
外部エンティティ同士は直接通信してはならない。すべての通信はシステムプロセスを経由しなければならない。たとえば「倉庫」がデータを「請求システム」に送信する場合、必ず「注文処理」プロセスを経由しなければならない。
5. データストアの数を制限する
データストアが多すぎると読者が混乱する。現在の詳細レベルに必要なストアのみを含めるべきである。ストアがレベル2でのみ使用される場合、レベル1に表示する必要はないかもしれない。
🚫 避けるべき一般的な誤り
経験豊富なアナリストですら誤りを犯す。これらの誤りを早期に認識することで、レビュー時の時間を節約できる。
- ブラックホール:出力のないプロセス。これはデータが消えていることを意味し、機能するシステムでは論理的に不可能である。
- ミラクル:入力のないプロセス。データは空から生成することはできない。
- グレイホール:入力はあるが、入力に基づいて期待される出力とは異なる出力を生成するプロセス。これは通常、論理が欠けていることを示している。
- 早すぎる詳細の記載:レベル1の承認前にレベル2の図を描くと、再作業を招く。階層構造に従って進めること。
- データストアの無視:データがどこに保存されているかを示さないことで、システムが一時的で信頼性が低いように見える。
📋 実装戦略
新しいプロジェクトでこれらの図を描くにはどうすればよいか?この構造化されたワークフローに従ってください。
フェーズ1:範囲定義
レベル0の図から始める。システム名とすべての外部エンティティを特定する。内部プロセスについてはまだ心配しないでください。境界についてプロジェクトスポンサーの承認を得る。
フェーズ2:機能分解
レベル1の図を作成する。主要なプロセスを特定する。すべてのデータストアが定義されていることを確認する。レベル0からのデータフローがここに存在することを検証する。ここがアーキテクチャが形作られる場所である。
フェーズ3:詳細な論理
レベル1から、説明が必要な複雑なプロセスを選択する。これらの特定領域に対してレベル2の図を作成する。開発者への引き継ぎや単体テスト仕様に使用する。
フェーズ4:保守
DFDは静的ではない。システムに変更が生じた際には図を更新する必要がある。古くなったDFDはまったくないよりも悪い。図はすべてのリリースサイクルごとに更新されるべきというルールを設ける。
🤝 他の技法との統合
DFDは孤立して存在するものではない。他のモデリング手法と組み合わせることで最も効果を発揮する。
- エンティティ関係図(ERD):DFDは動きを示す。ERDは構造を示す。DFDに表示されるデータストアを定義するためにERDを使用する。
- ユースケース図:ユースケース図はユーザーとのインタラクションに注目します。DFDはデータに注目します。要件文書作成において、互いに補完し合います。
- シーケンス図:シーケンス図はタイミングを示します。DFDは構造を示します。レベル2のプロセスにおけるデータフローのタイミングを明確にするために、シーケンス図を使用してください。
📝 使用法の要約
適切なDFDレベルを選択することは、対象読者と文書作成の目的に依存します。
- レベル0を使用する境界と範囲を定義するために。
- レベル1を使用するアーキテクチャと主要機能を定義するために。
- レベル2を使用する論理と実装の詳細を定義するために。
分解とバランスのルールを厳密に守ることで、システム開発の明確なロードマップを作成できます。この明確さにより、ビジネス関係者と技術チーム間の誤解が減少します。単に図を描くことではなく、データがビジネスにどのように貢献するかという共有された理解を確保することが目的であることを忘れないでください。
階層を正しく設定する時間を使うようにしてください。適切に構造化されたデータフロー図のセットは、あらゆるソフトウェアプロジェクトの開発および保守フェーズで大きな利益をもたらします。