











情報がシステム内でどのように移動するかを理解することは、成功にとって不可欠です。新しいプラットフォームの要件を定義している場合でも、既存のワークフローを監査している場合でも、データの流れを可視化することで、すべての関係者が同じ理解を持つことができます。データフロー図(DFD)は、まさにこの目的のために設計された強力なツールです。データがシステムに入り、どのように変化し、最終的にどこに到達するかを明確にします。非技術者向けのステークホルダーにとって、これらの図を読み解く力を身につけることで、ソフトウェア開発やビジネスプロセス分析における不透明さが解消されます。
このガイドでは、データフロー図の背後にある基本構成要素、記号、論理をわかりやすく解説します。世界中で標準的に使われている表記法、利用可能なさまざまな詳細レベル、そして一般的な誤りの見つけ方についても探求します。この文書の最後まで読み終えれば、図をレビューする自信を持ち、適切な質問をし、ビジネスプロセスが正確に表現されていることを確認できるようになります。
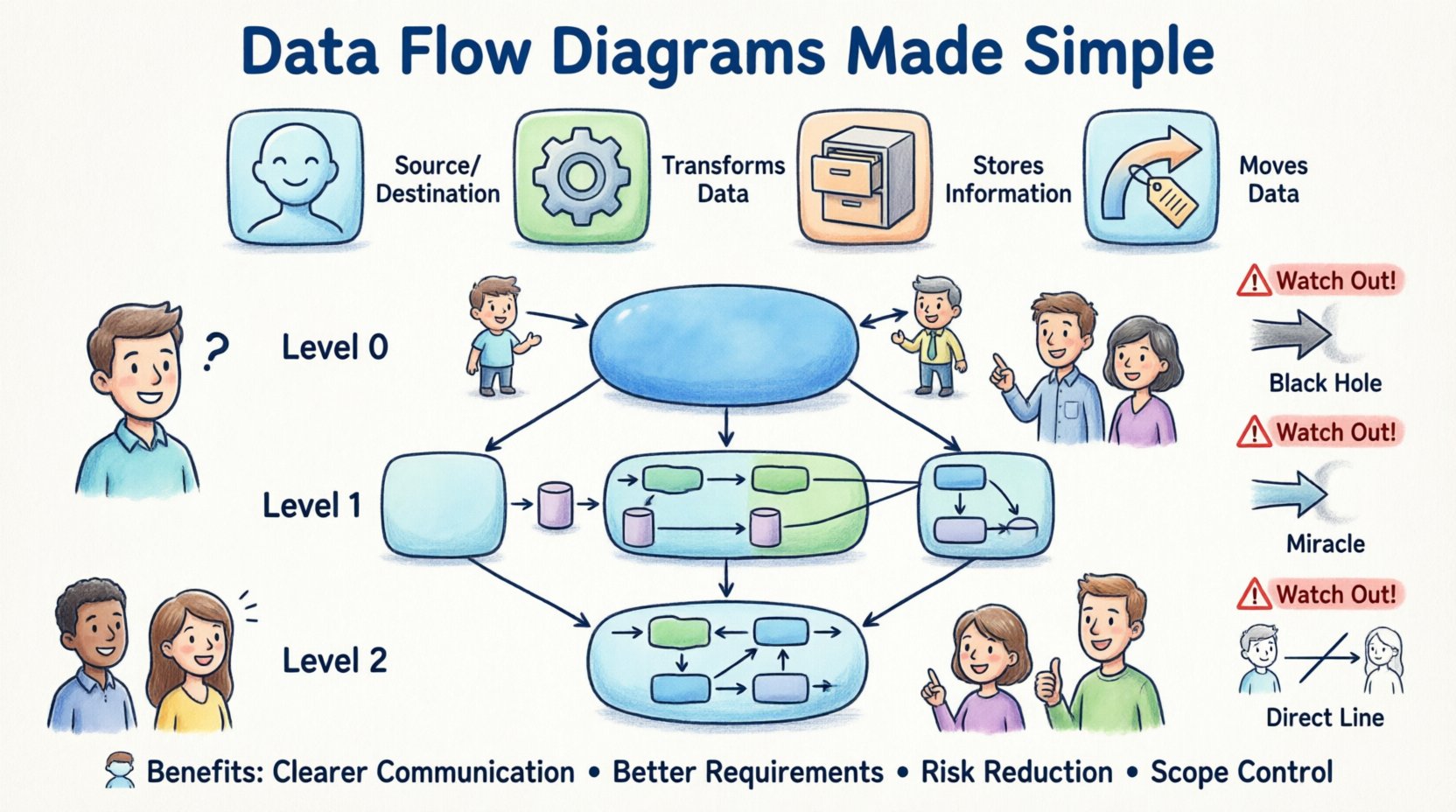
🧩 データフロー図とは何か?
データフロー図(DFD)は、情報システム内を流れているデータの流れを図式化したものです。フローチャートが制御の流れや決定の順序を示すのに対し、DFDはデータの移動にのみ焦点を当てます。従来のプログラミングにおける時間、ループ、条件分岐の論理とは無関係です。代わりに、以下の3つの根本的な問いに答えることを目的としています:
- データはどこから来るのか?(外部ソース)
- データには何が起こるのか?(プロセス)
- データはどこへ行くのか?(宛先または保存先)
DFDをデータの地図と考えてください。道路地図がすべての木や建物を示さないのと同じように、DFDはコードの詳細に巻き込まれることなく、情報の主要な経路を示します。この抽象化が、技術的な実装の「どうやって」ではなく、「何が」「どこへ」であるかを理解したいビジネス関係者にとって、非常に効果的である理由です。
🛑 DFD表記の4つの核心的な記号
あなたが遭遇する具体的な表記スタイルがどうであれ、すべてのDFDは4つの基本的な形状または概念に依存しています。これらの構成要素を理解することが、見ている図の意味を解きほぐす鍵となります。
1. 外部エンティティ(ソースまたは宛先) 👤
外部エンティティは、モデリングしているシステムの境界外に存在する人物、組織、またはシステムを表します。これはデータの出発点または最終受信者です。図では、これらは通常、長方形または正方形で表現されます。
- 例: 注文を行う顧客。
- 例:給与データを受け取る給与計算システム。
- 例:レポートの提出を求める規制当局。
重要なのは、図はエンティティが内部で何をしているかを示していないということです。システムとのやり取りだけを示しています。データがユーザーから来ている場合、ユーザーがエンティティです。データが銀行のAPIから来ている場合、銀行がエンティティです。
2. プロセス(アクション) ⚙️
プロセスは、入力データを出力データに変換するアクションを表します。ここが「作業」が行われる場所です。DFDでは、表記スタイルに応じて、通常は丸みを帯びた長方形または円で描かれます。すべてのプロセスには、少なくとも1つの入力と1つの出力が必要です。
- 例:注文の合計金額を計算する。
- 例:ログイン資格情報を検証する。
- 例:請求書のPDFを生成する。
プロセスは、動詞+名詞の形式で名前付けされます(たとえば「税金を計算する」ではなく「税金」だけではなく)。これにより、アクションが明確になります。プロセスは単に存在するだけではいけません。何らかの形でデータを変化させる必要があります。
3. データストア(記憶装置) 🗃️
データストアは、後で取得するために情報が保存される場所を表します。サーバー上の物理的なデータベースではなく、ストレージの論理的な表現です。図では、開かれた端を持つ長方形または平行線のように見えます。
- 例:顧客記録を含むファイル。
- 例:在庫レベルを保持するデータベーステーブル。
- 例:エラー追跡用の一時的なログファイル。
データストアは受動的です。自らデータを変更することはありません。プロセスが書き込みまたは読み込みを行うのを待っています。データストア(永続的または準永続的)とデータフロー(移動)の違いを明確にすることが重要です。
4. データフロー(移動) 🔄
データフローは、エンティティ、プロセス、ストア間でのデータの移動を示します。これらは矢印で表されます。矢印の方向がデータの流れを示し、矢印のラベルは、どのデータが移動しているかを正確に説明します。
- 例:「顧客注文」とラベル付けされた矢印が、エンティティからプロセスへ向かって移動しているもの。
- 例:「更新された在庫」とラベル付けされた矢印が、プロセスからデータストアへ向かって移動しているもの。
データフローは明確に名前を付けるべきです。「データ」や「情報」といった曖昧なラベルは避け、具体的な用語(例:「クレジットカード情報」や「配送先住所」)を使用してください。これにより、レビュー会議での混乱を防げます。
📐 記法スタイルの比較
業界では、DFD記法に2つの主要なスタイルがあります。同じ概念を表していますが、形状が異なります。違いを理解することで、異なるチームやベンダーが作成した文書を正しく解釈できるようになります。
| コンポーネント | Yourdon & DeMarco記法 | Gane & Sarson記法 |
|---|---|---|
| プロセス | 角が丸い長方形 | 角が丸い長方形 |
| 外部エンティティ | 長方形 | 長方形 |
| データストア | 開かれた端を持つ長方形 | 開かれた端を持つ長方形 |
| データフロー | 曲線矢印 | 直線矢印 |
両方のスタイルは有効です。Gane & Sarsonスタイルは、現代の企業環境ではよく好まれます。なぜなら、長方形の形状が標準的なUIデザインとよく整合するからです。しかし、Yourdon & DeMarcoスタイルは、レガシードキュメントで依然として広く使用されています。使用する形状に関わらず、論理は同じままです。
🏗️ DFDにおける詳細レベル
1つの図ではすべてを示すことはできません。複雑さを管理するために、DFDは異なる抽象度のレベルで作成されます。この階層構造により、ステークホルダーはまず全体像を把握でき、必要に応じて詳細に掘り下げることができます。
1. コンテキスト図(レベル0)🌍
コンテキスト図は、最も高い抽象度のレベルです。システム全体を中央の単一のプロセスとして示し、周囲に外部エンティティを配置しています。ここでは内部のデータストアやサブプロセスは表示されません。
- 目的: システムの境界を定義するため。
- 使用例: プロジェクトの初期段階で、システムの内部と外部を明確に合意するために使用される。
- 視覚的表現: システムを表す1つの円と、外部の長方形に接続する矢印。
ステークホルダーにとって、この図は「このシステムは私たちに何を提供するのか?」という問いに答えるものです。これはあなたが得られる最も高レベルの視点です。
2. レベル1図(機能分解)🔍
レベル1図は、コンテキスト図の単一プロセスを主要なサブプロセスに展開します。システムの主要な機能領域を明らかにします。ここでは、これらの主要機能間で情報が保持される場所を示すために、データストアが導入されます。
- 目的: 主要な機能コンポーネントを概説するため。
- 使用例: アーキテクチャの計画と、異なるチームへの作業割り当てに使用される。
- 視覚的表現: フローとストアで接続された複数のプロセス。
この段階で、ステークホルダーはすべての重要なビジネス機能がカバーされているか確認できます。この図に主要なビジネス要件に対応するプロセスが欠けている場合、追加する必要があります。
3. レベル2図(詳細な論理)🔬
レベル2図は、レベル1から特定のプロセスを取り出し、さらに分解します。複雑な計算や複雑なワークフローに使用されます。特定の機能のデバッグを行う場合を除き、非技術的なステークホルダーに示されるのはめったにありません。
- 目的: 特定のモジュールの詳細な論理を定義するため。
- 使用例: 開発チームの参照用および詳細なテスト計画用。
- 視覚的表現: 非常に細かい流れと意思決定ポイント。
ステークホルダーは、主にコンテキスト図とレベル1図に注目すべきである。レベル2図は通常、技術的な成果物であり、深さを提供するが、高レベルのレビューにおいて必ずしもビジネス価値があるわけではない。
🚦 DFDを効果的に読む方法
DFDを読むには体系的なアプローチが必要である。単に図の形状を見るのではなく、データの流れを追うべきである。これにより、情報のライフサイクルを理解できる。
ステップ1:境界を特定する
図を見て、システムの内部と外部にあるものを特定する。内部にあるものはすべてシステムによって制御される。外部にあるものはすべて外部の影響である。境界の外に存在するべきプロセスが存在する場合、それはスコープの問題である。
ステップ2:入力を追跡する
外部エンティティを見つける。システムに入力する矢印を追う。自分に問う:「このプロセスを開始するために必要なデータは何か?」データが欠けている場合、プロセスは機能しない。これにより、欠落している要件を特定できる。
ステップ3:変換を追う
一つのプロセスから次のプロセスへ移動する。問う:「データはどのように変化したか?」データがプロセスAからプロセスBへ流れている場合、Aの出力がBの入力となる。データ型が一致しない場合、設計上の欠陥がある。
ステップ4:ストレージを確認する
データストアを特定する。問う:「なぜこのデータが保存されているのか?」将来のレポートに必要か?過去の取引を再確認する必要があるか?プロセスがストアに書き込むが、他のプロセスがそれを読み込まない場合、そのストアは不要であり、コストを増加させる。
ステップ5:出力を検証する
システムから出る矢印を追う。正しい外部エンティティに到達しているか?システムがレポートを生成する場合、そのレポートがユーザーに届く経路があるか?図が行き止まりで終わる場合、システムは不完全である。
⚠️ DFDの一般的な誤りと異常
経験豊富なモデラーですら誤りを犯す。ステークホルダーとしてこれらの一般的な誤りを知ることで、レビュー中にそれらを発見できる。早期にこれらの問題を発見することで、開発の後半で大きな時間とコストの節約が可能になる。
1. ブラックホール
ブラックホールとは、プロセスに入力データはあるが、出力データがない状態を指す。データは入力され、消え、何も起こらない。実際のシステムでは、これは誤りである。ユーザーがフォームを送信した場合、システムはそれを保存するか、却下するか、確認を送信する必要がある。単に消えることはできない。
2. ミラクル
ミラクルはブラックホールの反対である。出力データはあるが、入力データがないプロセスを指す。データはどこから来たのか?システムが毎日のレポートを生成する場合、そのレポートを供給する入力トリガーまたはデータソースが存在しなければならない。データは空から生成することはできない。
3. エンティティとストアの間を直接データが流れている
データは、データストアに到達するまで、常にプロセスを経由しなければならない。ユーザーからデータベースに直接線を引くことはできない。トランザクションを処理するプロセス(例:「レコードを保存」)が存在しなければならない。これにより、保存前に検証や論理処理が適用される。
4. バランスの取れていない流れ
レベル0からレベル1に図を分解する際、入力と出力は一致しなければならない。コンテキスト図に「注文」が入力されている場合、レベル1図にも「注文」が入力されているべきである。もし消失している場合、分解はバランスが取れておらず、正確ではない。
5. 円形のデータフロー
データは処理されずに円を描いて流れることはあってはならない。プロセスAがデータをプロセスBに送り、プロセスBがデータをプロセスAに送り返す場合、その間にデータストアや外部の変化がないと、無限ループが発生する。これはプロセスフローに論理的な誤りがあることを示している。
🤝 非技術的ステークホルダーへの利点
なぜこの表記法を学ぶことに気を配るべきなのか?その利点は、図を理解するという範囲を越えて、プロジェクトにおけるあなたの役割を大きく向上させる。
より良い要件収集
DFDを理解することで、要件の穴を発見できる。ステークホルダーが「ユーザーのログインを追跡する必要がある」と言うが、図に認証のためのプロセスが表示されていない場合、すぐにこれを指摘できる。あなたは受動的な観察者ではなく、能動的な検証者となる。
より明確なコミュニケーション
言葉は曖昧になり得ます。「データを保存する」という表現は、「ファイルに保存する」ことを意味する場合もあれば、「データベースに保存する」ことを意味する場合もあります。DFDはその目的地を視覚的に明確にします。これにより、ビジネスチームと技術チームの間での誤解が減ります。全員が同じ地図を見て、目的地について合意することができます。
リスク低減
設計段階で見つかった誤りは修正が安価です。コード作成後に見つかる誤りは高価です。開発を始める前にDFDを確認することで、論理的な欠陥を早期に発見できます。これにより、意図せず動作しない機能を開発するためのリソースの無駄を防ぐことができます。
範囲管理
DFDは境界を明確に定義します。システムの内部と外部の内容を示します。これにより、「スコープクリープ」を防ぐことができます。ステークホルダーが定義されたエンティティやプロセスの外にある新しい機能を要求した場合、DFDはその要求を管理するための視覚的証拠を提供します。
🔧 DFDの維持におけるベストプラクティス
図は正確でなければ、意味がありません。時間の経過とともにシステムは変化し、図は古くなってしまいます。長期的な成功のためには、図を最新の状態に保つことが不可欠です。
- バージョン管理:DFDをコードのように扱いましょう。重要な変更が生じた時点でバージョンを保存してください。これにより、システムの変遷を追跡できます。
- レビューのサイクル:図の定期的なレビューをスケジュールしましょう。危機が起きてから確認するのではなく、四半期ごとのレビューで、現在のビジネスニーズと整合していることを確認します。
- ステークホルダーの承認:開発を開始する前に、主要なステークホルダーがレベル1の図に署名することを確認してください。この正式な合意により、モデルがビジネスの期待に合致していることが検証されます。
- 完全性よりも明確性を優先する:データストア内のすべてのフィールドを表示しようとしないでください。論理的な流れに注目してください。詳細が多すぎると、図の主な目的が見えにくくなります。
- 一貫した命名:すべての図で同じ用語を使用してください。ある場所では「Customer」と呼び、別の場所では「Client」と呼ぶと、混乱を招きます。用語の用語集を維持しましょう。
📝 結論
データフローダイアグラムは単なる技術的な図面以上のものであり、ビジネス目標と技術的実行の間をつなぐコミュニケーションツールです。4つの基本的な記号を理解し、異なる詳細レベルを識別し、一般的な誤りを特定する方法を知ることで、システムプロジェクトの管理において大きな優位性を得られます。
これらの図から価値を得るには、開発者である必要はありません。情報の流れを理解するだけで十分です。この知識により、より良い質問をし、仮定を疑い、最終製品が本当にビジネスニーズを満たしていることを保証できます。システムがますます複雑化する中で、明確で視覚的な文書化の必要性はさらに重要になります。DFD表記の基本を習得することは、より明確で効率的なプロジェクトの納品に向けての一歩です。
思い出してください。完璧な図を描くことが目的ではなく、理解の明確さが目的です。これらの図を使って会話の促進、リスクの特定、チームのシステムビジョンへの合意形成を図りましょう。DFD表記の基礎をしっかり押さえれば、システム設計の複雑さを自信と正確さを持って乗り越えることができます。