











Die Erstellung robuster Systemmodelle erfordert einen disziplinierten Ansatz dafür, wie Informationen erfasst, bewegt und gespeichert werden. Im Kontext von Datenflussdiagrammen (DFD) stellt der Datenspeicher die Grundlage der Systempersistenz dar. Ohne eine klare Gestaltung dafür, wo Daten gespeichert werden, bleibt der Informationsfluss abstrakt und nicht umsetzbar. Dieser Leitfaden untersucht die zentralen Prinzipien der Gestaltung von Datenspeichern innerhalb von DFDs, um Klarheit, Genauigkeit und Übereinstimmung mit der Systemarchitektur sicherzustellen.
Eine effektive Modellierung geht über das Zeichnen von Linien zwischen Formen hinaus. Sie erfordert ein tiefes Verständnis für Datenintegrität, Zugriffsmuster und den Lebenszyklus von Informationen innerhalb des Systems. Durch Einhaltung etablierter Gestaltungsprinzipien können Analysten Diagramme erstellen, die als zuverlässige Baupläne für Entwicklungsteams dienen.
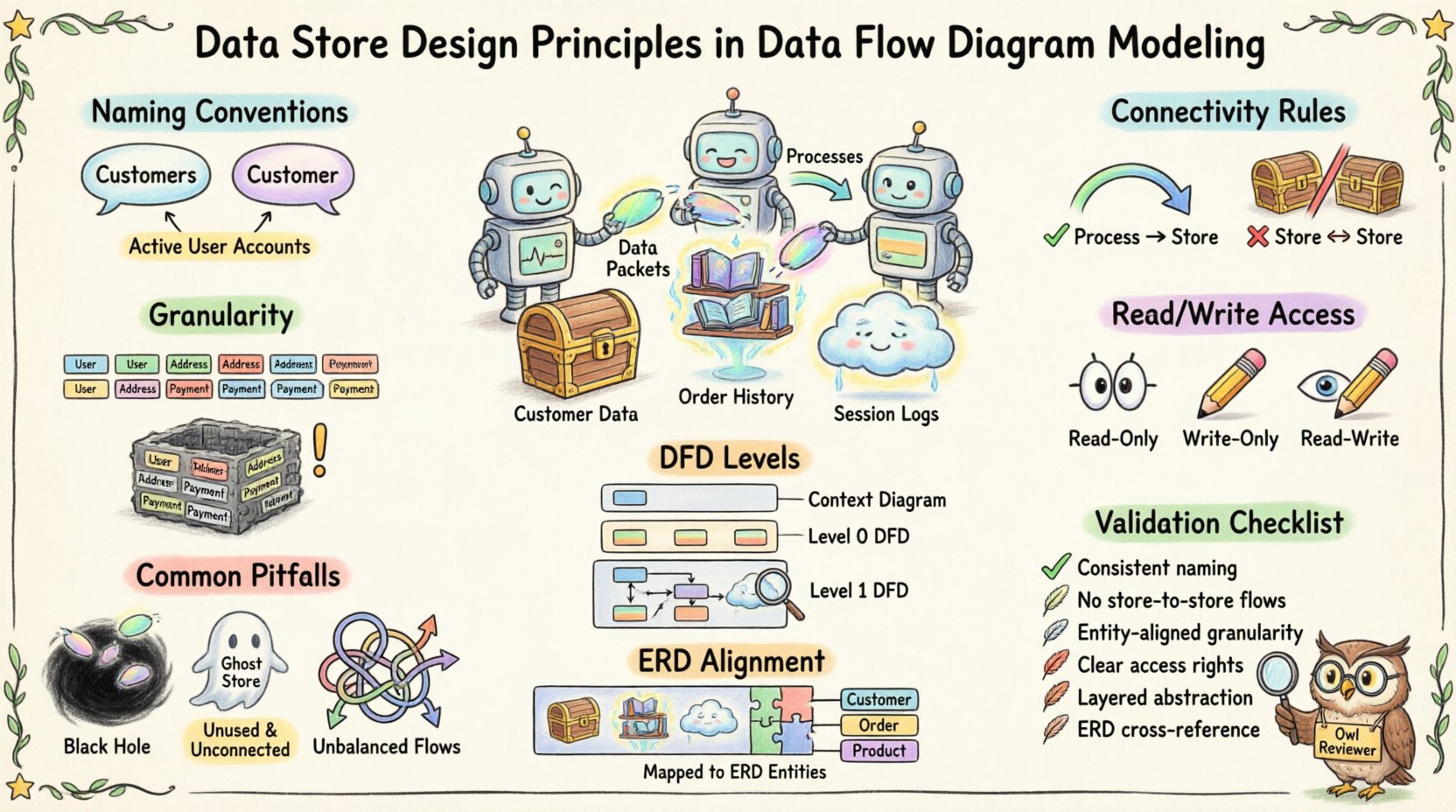
🏷️ Definition des Datenspeichers 🏷️
Ein Datenspeicher ist ein passives Element in einem Datenflussdiagramm. Im Gegensatz zu Prozessen, die Daten verändern, halten Datenspeicher Daten in Ruhe. Sie stellen Dateien, Datenbanken, Papierakten oder jedes andere Repository dar, in dem Informationen für eine spätere Abrufung gespeichert werden.
- Passive Natur:Daten fließen nicht aus einem Speicher heraus, es sei denn, ein Prozess fordert sie ausdrücklich an.
- Speicheridentität:Es ist selbst kein Prozess; es verändert die Daten nicht, sondern hält sie lediglich.
- Visuelle Darstellung:Typischerweise dargestellt als offener Rechteck oder doppelte senkrechte Linien, abhängig vom verwendeten Notationssystem.
Beim Gestalten dieser Elemente muss der Fokus auf der logischen Anforderung liegen, nicht auf der physischen Implementierung. Das DFD beschreibt wasDaten benötigt werden, nicht wiesie physisch indiziert oder auf einer Festplatte gespeichert werden.
📝 Namenskonventionen zur Klarheit 📝
Die Namensgebung ist die erste Verteidigungslinie gegen Verwirrung. Mehrdeutige Bezeichnungen führen zu Missverständnissen während der Entwurfsphase. Ein gut benannter Datenspeicher liefert sofortigen Kontext über die darin enthaltenen Informationen.
1. Singular vs. Plural
Konsistenz ist entscheidend. Einige Teams bevorzugen Singular-Nomen (z. B. Kunde), während andere Plural verwenden (z. B. Kunden). Der entscheidende Faktor ist, dass das gesamte Modell die gleiche Konvention verwendet.
- Empfehlung:Verwenden Sie Plural-Nomen für Datensätze (z. B. Bestellungen, Produkte) um eine Sammlung zu implizieren.
- Ausnahme:Einzelne Namen funktionieren für spezifische Instanzen, wenn der Speicher nur einen Datensatztyp enthält (z. B. Konfiguration).
2. Beschreibende Genauigkeit
Vermeiden Sie generische Begriffe wie Daten oder Info. Diese Beschriftungen geben keinerlei Einblick in den Inhalt.
- Schlechtes Beispiel: Systemdaten
- Gutes Beispiel: Aktive Benutzerkonten
Spezifische Benennung hilft den Stakeholdern, den Umfang des Speichers sofort zu erkennen. Sie verringert die kognitive Belastung, die zur Verständnis des Diagramms erforderlich ist.
3. Zeitform und Zustand
Die Namen sollten den Zustand der Daten widerspiegeln. Wenn der Speicher historische Aufzeichnungen enthält, sollte der Name dies widerspiegeln.
- Transaktionsprotokolle bedeutet eine Aufzeichnung vergangener Ereignisse.
- Ausstehende Bestellungen bedeutet Daten, die auf eine Aktion warten.
🔗 Verbindungsregeln 🔗
Die Bewegung von Daten in und aus einem Speicher wird strengen logischen Regeln unterworfen. Die Verletzung dieser Regeln zerstört die Integrität des DFD.
1. Anforderung an die Prozessverbindung
Ein Datenspeicher muss immer mit mindestens einem Prozess verbunden sein. Er kann nicht isoliert existieren.
- Eingabe: Ein Prozess muss Daten in den Speicher schreiben (z. B. Speichern eines neuen Datensatzes).
- Ausgabe: Ein Prozess muss Daten aus dem Speicher lesen (z. B. Abrufen eines Datensatzes).
Wenn ein Speicher mit nichts verbunden ist, ist er ein geisterhafter Element ohne Funktion. Wenn er mit mehreren Prozessen verbunden ist, muss der Datenfluss für jede Verbindung klar definiert sein.
2. Kein direkter Datenfluss zwischen Speichern
Daten können nicht direkt von einem Datenspeicher zu einem anderen gelangen, ohne dass dazwischen ein Prozess steht. Diese Regel setzt das Prinzip durch, dass Datenumwandlung oder -überprüfung vor der Speicherung erfolgt.
- Falsch: Linie, die verbindet Speicher A direkt mit Speicher B.
- Richtig: Prozess X liest aus Speicher A, transformiert die Daten und schreibt in Speicher B.
Diese Trennung stellt sicher, dass Geschäftslogik, Überprüfung oder Formatierung vor der Dauerhaftigkeit der Daten angewendet wird. Sie verhindert, dass das Modell suggeriert, dass Daten einfach kopiert werden, ohne Überwachung.
3. Kennzeichnung von Datenflüssen
Jede Linie, die einen Prozess mit einem Datenspeicher verbindet, muss beschriftet sein. Die Beschriftung beschreibt die spezifischen Daten, die diese Grenze überschreiten.
- Beispiel: Eine Linie von Auftragsprozess zu Auftragspeicher könnte beschriftet sein mit Auftragsdetails.
- Beispiel: Eine Linie von Auftragspeicher zu Berichterstattungsprozess könnte als Bestellverlauf.
Beschriftungen geben Kontext für das Volumen und die Art der übertragenen Daten. Sie helfen Entwicklern, die Schema-Anforderungen später besser zu verstehen.
🎯 Feinheit und Umfang 🎯
Die Entscheidung, wie Daten in Speicher aufgeteilt werden, ist eine entscheidende Gestaltungsentscheidung. Zu viele Speicher fragmentieren das Modell, während zu wenige ein monolithisches Informationsblock erzeugen.
1. Gruppierung nach Entitäten
Gruppieren Sie Daten nach logischen Entitäten. Wenn das System Kunden, Produkte und Rechnungen verfolgt, sollten diese in der Regel in separaten Speichern gehalten werden.
- Vorteil: Vereinfacht die Wartung. Änderungen an Kundendaten beeinflussen die Speicherlogik für Rechnungen nicht.
- Vorteil: Verringert das Risiko einer versehentlichen Datenbeschädigung während Aktualisierungen.
2. Trennung von Lesen und Schreiben
Überlegen Sie, ob ein Speicher hauptsächlich zum Lesen oder Schreiben dient. Hochvolumige Transaktionsprotokolle erfordern oft eine andere Speicherhandhabung als Referenzdaten.
- Referenzdaten: Speicher wie Ländercodes sind leseschwer und ändern sich selten.
- Transaktionsdaten: Speicher wie Verkaufsprotokolle sind schreibschwer und wachsen im Laufe der Zeit.
Die Unterscheidung dieser Arten hilft bei der Planung von Kapazität und Zugriffsmustern, auch wenn das DFD weiterhin ein logisches Modell bleibt.
3. Temporär gegenüber Dauerhaft
Nicht alle Datenspeicher stehen für dauerhafte Speicherung. Einige sind temporäre Puffer.
- Sitzungsdaten: Speicher, die für temporäre Benutzersitzungen während eines Anmeldevorgangs verwendet werden.
- Cache-Speicher: Temporäre Aufbewahrungsorte für häufig abgerufene Daten.
Durch eindeutiges Kennzeichnen von temporären Speichern wird Verwirrung bezüglich der Datenhaltungsrichtlinien vermieden. Ein temporärer Speicher sollte geleert oder gelöscht werden, sobald der Prozess abgeschlossen ist.
🔄 Datenfluss und Prozessinteraktion 🔄
Die Beziehung zwischen einem Prozess und einem Datenspeicher ist in vielen Fällen bidirektional, aber nicht immer. Das Verständnis der Richtungsrichtung ist für eine genaue Modellierung unerlässlich.
1. Lesezugriff
Einige Speicher werden nur zum Lesen zugegriffen. Ein Prozess könnte einen Speicher abfragen, um Informationen anzuzeigen, ohne diese zu verändern.
- Beispiel: Ein Profil anzeigen Prozess liest aus Benutzerprofil-Speicher.
- Einschränkung: Es sollte kein Datenfluss-Pfeil vom Speicher zum Prozess UND zurück für dieselbe Transaktion geben, es sei denn, es impliziert eine Schreiboperation.
2. Schreibzugriff
Einige Prozesse schreiben Daten, ohne sie zuerst abrufen zu müssen.
- Beispiel: Ein Ereignisprotokoll Prozess schreibt in System-Audit-Speicher.
- Einschränkung: Stellen Sie sicher, dass der Prozess über den notwendigen Kontext verfügt, um die Daten korrekt ohne externe Eingaben zu schreiben.
3. Lese- und Schreibzugriff
Die meisten Geschäftsprozesse beinhalten das Abrufen, Ändern und Speichern von Daten.
- Beispiel: Bestand aktualisieren liest den aktuellen Bestand, berechnet den neuen Betrag und speichert ihn.
- Modellierung: Verwenden Sie getrennte Flüsse für Lesen und Schreiben, um die Reihenfolge der Operationen zu klären.
Diese Unterscheidung hilft Entwicklern zu verstehen, ob eine Datenbanktransaktion sofort eine Sperrung oder eine Commit-Operation erfordert.
📊 DFD-Ebenen und Sichtbarkeit von Datenspeichern 📊
DFDs werden oft in Ebenen zerlegt, von Kontextdiagrammen (Ebene 0) bis hin zu detaillierten Aufteilungen (Ebene 2, Ebene 3). Datenspeicher erscheinen auf jeder Ebene unterschiedlich.
1. Kontextebene (Ebene 0)
Auf der höchsten Ebene werden Datenspeicher oft weggelassen, um die Einfachheit zu bewahren. Der Fokus liegt auf externen Entitäten und der Hauptsystemgrenze.
- Grund:Zu viel Detail verschleiert den datengetriebenen Austausch auf hoher Ebene.
- Ausnahme:Wichtige externe Datenbanken könnten gezeigt werden, wenn sie für die Systemgrenze entscheidend sind.
2. Ebene 1-Zerlegung
Wenn das System in Hauptprozesse zerlegt wird, werden Datenspeicher sichtbar. Hier wird die primäre Speicherarchitektur definiert.
- Schwerpunkt:Identifizieren Sie die zentralen Speicherorte, die für jede Hauptfunktion erforderlich sind.
- Detail:Stellen Sie sicher, dass jeder Prozess einen Zielort für seine Ausgabedaten hat.
3. Ebene 2 und darüber
Weitere Zerlegung kann große Datenspeicher in kleinere, spezifischere aufteilen.
- Beispiel: Kunden-Speicher auf Ebene 1 könnte sich aufteilen in Kontaktinformations-Speicher und Rechnungs-Speicher auf Ebene 2.
- Konsistenz:Stellen Sie sicher, dass die Daten auf niedrigeren Ebenen mit den Daten auf höheren Ebenen übereinstimmen. Führen Sie keine neuen Datentypen ein, die im Eltern-Diagramm nicht vorhanden waren.
⚠️ Häufige Fehler ⚠️
Sogar erfahrene Analysten begehen Fehler bei der Gestaltung von Datenspeichern. Das Vermeiden dieser häufigen Fehler stellt sicher, dass das Diagramm korrekt bleibt.
- Schwarze Löcher:Ein Prozess, der Daten entgegennimmt, aber nirgends speichert. Dies deutet auf Datenverlust hin.
- Feuerstürme: Ein Prozess, der Daten entgegennimmt, aber ohne Speicher Daten erzeugt. Dies bedeutet, dass Daten aus dem Nichts entstehen (Wunder).
- Geister-Speicher: Datenspeicher ohne angeschlossene Prozesse. Das sind Sackgassen.
- Ungleichgewogene Flüsse: Beim Übergang von Ebene 1 zu Ebene 2 müssen Eingaben und Ausgaben übereinstimmen. Wenn in Ebene 2 ein Speicher hinzugefügt wird, muss er durch die Eingaben/Ausgaben des übergeordneten Prozesses gerechtfertigt werden.
- Überdimensionierung: Versuch, jede Datenbanktabelle als separaten Speicher in einem Diagramm der Ebene 1 zu modellieren. Bleiben Sie bei logischen Entitäten, nicht bei physischen Tabellen.
📚 Ausrichtung an Datenmodellen 📚
Während DFDs auf Flüsse fokussieren, müssen sie mit Entitäts-Beziehungs-Diagrammen (ERD) oder logischen Datenmodellen übereinstimmen. Die Datenspeicher im DFD sollten den Entitäten im ERD entsprechen.
- Konsistenzprüfung: Wenn das DFD einen Produkt-Speicher, dann sollte das ERD eine ProduktEntität haben.
- Attribut-Zuordnung: Die Attribute, die der Prozess benötigt, um mit dem Speicher zu interagieren, müssen im Datenmodell vorhanden sein.
- Normalisierung: Obwohl DFDs keine Normalisierung erzwingen, sollte die Gestaltung offensichtliche Redundanzen vermeiden, die auf eine schlechte Datenbankgestaltung hindeuten.
Diese Ausrichtung stellt sicher, dass die logische Gestaltung (DFD) in die physische Umsetzung (Datenbank-Schema) ohne erheblichen Umgestaltungsbedarf übertragen werden kann.
🔍 Überprüfungsliste zur Gestaltungsvalidierung 🔍
Bevor ein Datenflussdiagramm endgültig festgelegt wird, verwenden Sie die folgende Liste, um die Gestaltung der Datenspeicher zu überprüfen.
| Grundsatz | Punkt der Überprüfungsliste | Status |
|---|---|---|
| Benennung | Sind alle Speichernamen beschreibend und konsistent? | ☐ |
| Anschlussfähigkeit | Ist jeder Speicher mit mindestens einem Prozess verbunden? | ☐ |
| Flussrichtung | Weisen die Pfeile korrekt zwischen Prozessen und Speichern? | ☐ |
| Beschriftung | Fließt Daten über Linien, die mit Inhaltsspezifikationen beschriftet sind? | ☐ |
| Keine direkten Speicherverbindungen | Gibt es Linien, die Speicher direkt miteinander verbinden? | ☐ |
| Konsistenz | Passen die Speicher auf niedrigerer Ebene dem Umfang der übergeordneten Ebene? | ☐ |
| Integrität | Werden alle Datenanforderungen für Prozesse durch verfügbare Speicher erfüllt? | ☐ |
🔄 Wartung und Evolution 🔄
Systemanforderungen ändern sich. Datenbanken müssen an diese Änderungen anpassbar sein, ohne das Modell zu beschädigen.
- Versionskontrolle: Verfolgen Sie Änderungen an Speicherdefinitionen. Wenn ein Speicher aufgeteilt wird, dokumentieren Sie den Migrationspfad.
- Veraltete Daten: Planen Sie, wie alte Daten behandelt werden, wenn sich die Speicherschema ändert. Dies erfordert oft einen Archivspeicher.
- Feedback-Schleife: Nutzen Sie Feedback von Entwicklerteams, um die Granularität des Speichers zu verfeinern. Wenn Entwickler einen Speicher zu groß finden, teilen Sie ihn auf. Wenn sie ihn zu fragmentiert finden, vereinigen Sie ihn.
Ein statisches Modell ist eine Belastung. Der Datenbankentwurf sollte überprüft werden, sobald sich Geschäftsregeln ändern oder neue Compliance-Anforderungen eingeführt werden. Dadurch bleibt das DFD ein lebendiges Dokument, das die Datenbedürfnisse des Systems genau widerspiegelt.
📝 Schlussfolgerung zur Umsetzung
Die Gestaltung von Datenbanken in Datenflussdiagrammen ist eine grundlegende Aufgabe für die Systemanalyse. Sie schließt die Lücke zwischen abstrakten Prozessen und konkreter Datenpersistenz. Durch die Einhaltung strenger Namenskonventionen, Verbindungsregeln und Granularitätsprinzipien erstellen Analysten Modelle, die sowohl lesbar als auch umsetzbar sind.
Das Ziel besteht nicht darin, die Datenbankstruktur perfekt zu replizieren, sondern die logische Notwendigkeit der Datenhaltung zu erfassen. Wenn das DFD genau ist, verläuft der Übergang in die Entwicklung reibungsloser, und das Risiko von Datenverlust oder Fehlausrichtung wird erheblich reduziert. Konzentrieren Sie sich auf Klarheit, Konsistenz und den logischen Informationsfluss, um hochwertige Systemdesigns zu erzeugen.