











Criar modelos de sistemas robustos exige uma abordagem disciplinada sobre como as informações são capturadas, movidas e mantidas. No contexto de Diagramas de Fluxo de Dados (DFD), o armazenamento de dados representa a base da persistência do sistema. Sem um projeto claro sobre onde os dados residem, o fluxo de informações permanece abstrato e não implementável. Este guia explora os princípios fundamentais do design de armazenamentos de dados dentro dos DFDs, garantindo clareza, precisão e alinhamento com a arquitetura do sistema.
A modelagem eficaz vai além de desenhar linhas entre formas. Exige um entendimento profundo da integridade dos dados, dos padrões de acesso e do ciclo de vida da informação dentro do sistema. Ao seguir princípios de design estabelecidos, analistas podem produzir diagramas que servem como plantas confiáveis para equipes de desenvolvimento.
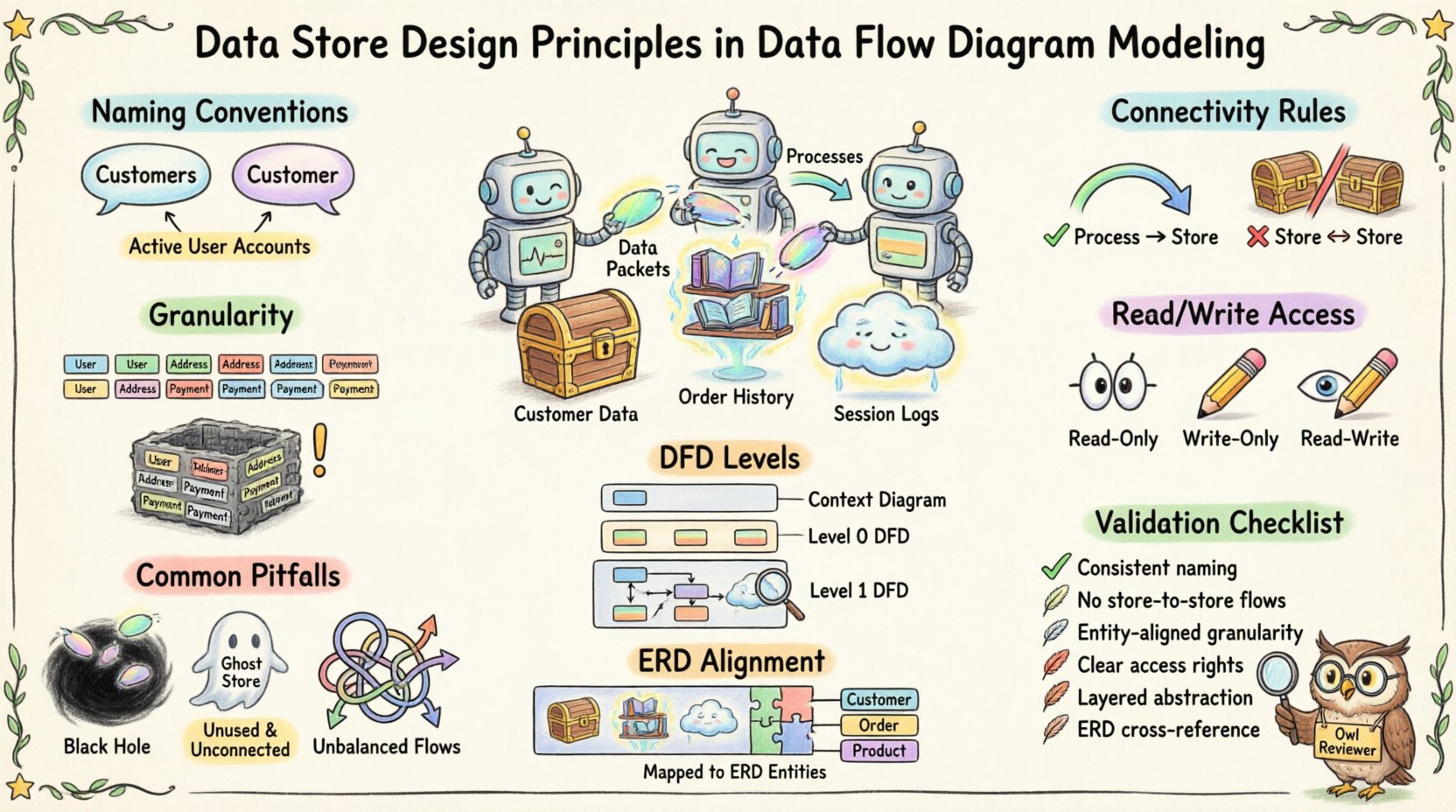
🏷️ Definindo o Armazenamento de Dados 🏷️
Um armazenamento de dados é um elemento passivo em um Diagrama de Fluxo de Dados. Diferentemente dos processos, que transformam dados, os armazenamentos de dados mantêm dados em repouso. Eles representam arquivos, bancos de dados, registros em papel ou qualquer repositório onde as informações são salvas para recuperação posterior.
- Natureza Passiva:Os dados não saem de um armazenamento a menos que um processo solicite explicitamente.
- Identidade do Armazenamento:Ele não é um processo em si; não altera os dados, apenas os mantém.
- Representação Visual:Normalmente representado como um retângulo com uma extremidade aberta ou duas linhas verticais duplas, dependendo do padrão de notação utilizado.
Ao projetar esses elementos, o foco deve permanecer na exigência lógica, e não na implementação física. O DFD descreveo queos dados necessários, e nãocomoeles são fisicamente indexados ou armazenados em um disco rígido.
📝 Convenções de Nomeação para Clareza 📝
A nomeação é a primeira linha de defesa contra a confusão. Rótulos ambíguos levam a mal-entendidos durante a fase de projeto. Um armazenamento de dados bem nomeado fornece contexto imediato sobre as informações que contém.
1. Singular vs. Plural
A consistência é fundamental. Algumas equipes preferem substantivos no singular (por exemplo, Cliente) enquanto outras usam o plural (por exemplo, Clientes). O fator crítico é que todo o modelo use a mesma convenção.
- Recomendação:Use substantivos no plural para conjuntos de dados (por exemplo, Pedidos, Produtos) para indicar uma coleção.
- Exceção:Nomes singulares funcionam para instâncias específicas se o armazenamento contém apenas um tipo de registro (por exemplo, Configuração).
2. Precisão Descritiva
Evite termos genéricos como Dados ou Info. Esses rótulos não fornecem nenhuma informação sobre o conteúdo.
- Exemplo Ruim: Dados do Sistema
- Exemplo Bom: Contas de Usuários Ativos
Nomes específicos ajudam os interessados a identificar imediatamente o escopo do armazenamento. Isso reduz a carga cognitiva necessária para entender o diagrama.
3. Tempo e Estado
Os nomes devem refletir o estado dos dados. Se o armazenamento contém registros históricos, o nome deve refletir isso.
- Logs de Transações implica um registro de eventos passados.
- Pedidos Pendentes implica dados aguardando ação.
🔗 Regras de Conectividade 🔗
O movimento de dados para dentro e para fora de um armazenamento é regido por regras lógicas estritas. Violar essas regras compromete a integridade do DFD.
1. Requisito de Conexão com Processo
Um armazenamento de dados deve sempre estar conectado a pelo menos um processo. Ele não pode existir isolado.
- Entrada: Um processo deve gravar dados no armazenamento (por exemplo, salvando um novo registro).
- Saída: Um processo deve ler dados do armazenamento (por exemplo, recuperando um registro).
Se um armazenamento está conectado a nada, é um elemento fantasma sem função. Se estiver conectado a múltiplos processos, o fluxo de dados deve ser claramente definido para cada conexão.
2. Nenhum fluxo direto de armazenamento para armazenamento
Os dados não podem se mover diretamente de um armazenamento de dados para outro sem um processo intermediário. Esta regra reforça o princípio de que a transformação ou validação dos dados ocorre antes do armazenamento.
- Incorreto: Linha conectando Armazenamento A diretamente a Armazenamento B.
- Correto: Processo X lê de Armazenamento A, transforma os dados e grava em Armazenamento B.
Essa separação garante que a lógica de negócios, validação ou formatação seja aplicada antes que os dados sejam persistidos. Isso evita que o modelo sugira que os dados são simplesmente copiados sem supervisão.
3. Rotulagem de Fluxo de Dados
Toda linha que conecta um processo a um armazenamento de dados deve ser rotulada. A rotulação descreve os dados específicos que estão se movendo por essa fronteira.
- Exemplo: Uma linha de Processo de Pedido para Armazenamento de Pedidos pode ser rotulada como Detalhes do Pedido.
- Exemplo: Uma linha de Armazenamento de Pedidos para Processo de Relatório pode ser rotulado comoHistórico de Pedidos.
Rótulos fornecem contexto sobre o volume e o tipo de dados sendo transferidos. Eles ajudam os desenvolvedores a entenderem os requisitos de esquema posteriormente.
🎯 Granularidade e Escopo 🎯
Decidir como dividir os dados em armazenamentos é uma decisão de design crítica. Muitos armazenamentos fragmentam o modelo, enquanto poucos criam um bloco monolítico de informações.
1. Agrupamento Baseado em Entidade
Agrupe os dados por entidade lógica. Se o sistema rastreia clientes, produtos e faturas, esses geralmente devem residir em armazenamentos separados.
- Benefício:Simplifica a manutenção. Alterações nos dados do cliente não afetam a lógica de armazenamento de faturas.
- Benefício:Reduz o risco de corrupção acidental de dados durante atualizações.
2. Separação de Leitura e Escrita
Considere se um armazenamento é principalmente para leitura ou escrita. Registros de transações de alto volume frequentemente exigem tratamento de armazenamento diferente dos dados de referência.
- Dados de Referência: Armazenamentos comoCódigos de País são de leitura intensiva e raramente mudam.
- Dados de Transação: Armazenamentos comoLogs de Vendas são de escrita intensiva e crescem ao longo do tempo.
Distinguir esses tipos ajuda na planejamento de capacidade e padrões de acesso, mesmo que o DFD permaneça um modelo lógico.
3. Temporário vs. Permanente
Nem todos os armazenamentos de dados representam retenção permanente. Alguns são buffers temporários.
- Dados de Sessão: Armazenamentos usados para sessões temporárias de usuários durante um processo de login.
- Armazenamentos de Cache: Áreas temporárias de armazenamento para dados frequentemente acessados.
Marcar claramente as lojas temporárias evita confusão sobre as políticas de retenção de dados. Uma loja temporária deve ser esvaziada ou limpa assim que o processo for concluído.
🔄 Fluxo de Dados e Interação de Processos 🔄
A relação entre um processo e uma loja de dados é bidirecional em muitos casos, mas nem sempre. Compreender a direcionalidade é essencial para um modelagem precisa.
1. Acesso Somente Leitura
Algumas lojas são acessadas apenas para leitura. Um processo pode consultar uma loja para exibir informações sem modificá-las.
- Exemplo: Um Exibir Perfil processo lendo de Loja de Perfil de Usuário.
- Restrição:Nenhuma seta de fluxo de dados deve apontar da loja para o processo E de volta para a mesma transação, a menos que implique uma operação de escrita.
2. Acesso Somente Escrita
Alguns processos escrevem dados sem precisar recuperá-los primeiro.
- Exemplo: Um Registro de Eventos processo escrevendo em Loja de Auditoria do Sistema.
- Restrição:Garanta que o processo tenha o contexto necessário para escrever os dados corretamente sem entrada externa.
3. Acesso Leitura-Escrita
A maioria dos processos de negócios envolve recuperar, modificar e salvar dados.
- Exemplo: Atualizar Estoque lê o estoque atual, calcula a nova quantidade e salva-a.
- Modelagem: Use fluxos separados para leitura e escrita para esclarecer a sequência de operações.
Essa distinção ajuda os desenvolvedores a entenderem se uma transação de banco de dados exige um bloqueio ou um commit imediatamente.
📊 Níveis de DFD e Visibilidade de Armazenamento 📊
Os DFDs são frequentemente decompostos em níveis, desde Diagramas de Contexto (Nível 0) até análises detalhadas (Nível 2, Nível 3). Os armazenamentos de dados aparecem de forma diferente em cada nível.
1. Nível de Contexto (Nível 0)
No nível mais alto, os armazenamentos de dados são frequentemente omitidos para manter a simplicidade. O foco está nas entidades externas e na fronteira principal do sistema.
- Motivo:Demasiados detalhes obscurecem a troca de dados de alto nível.
- Exceção:Bancos de dados externos importantes podem ser mostrados se forem críticos para a fronteira do sistema.
2. Decomposição do Nível 1
À medida que o sistema é dividido em processos principais, os armazenamentos de dados tornam-se visíveis. É aqui que a arquitetura principal de armazenamento é definida.
- Foco:Identifique os repositórios principais necessários para cada função principal.
- Detalhe:Garanta que cada processo tenha um destino para seus dados de saída.
3. Nível 2 e Além
A decomposição adicional pode dividir grandes armazenamentos de dados em outros menores e mais específicos.
- Exemplo: Armazenamento de Cliente no Nível 1 pode ser dividido em Armazenamento de Informações de Contato e Armazenamento de Faturamento no Nível 2.
- Consistência:Garanta que os dados nos níveis inferiores correspondam aos dados nos níveis superiores. Não introduza novos tipos de dados que não estejam presentes no diagrama pai.
⚠️ Armadilhas Comuns ⚠️
Mesmo analistas experientes cometem erros ao projetar armazenamentos de dados. Evitar esses erros comuns garante que o diagrama permaneça preciso.
- Buracos Negros:Um processo que recebe dados, mas não os escreve em lugar algum. Isso implica perda de dados.
- Fogarés: Um processo que recebe dados de entrada, mas gera dados de saída sem armazenamento. Isso implica que os dados são criados do nada (milagre).
- Armazenamentos Fantasma: Armazenamentos de dados sem processos conectados. São pontos sem saída.
- Fluxos Desbalanceados: Ao passar do Nível 1 para o Nível 2, as entradas e saídas devem corresponder. Se um armazenamento for adicionado no Nível 2, deve ser justificado pelas entradas/saídas do processo pai.
- Engenharia Excessiva: Tentar modelar cada tabela do banco de dados como um armazenamento separado em um diagrama do Nível 1. Mantenha-se em entidades lógicas, não em tabelas físicas.
📚 Alinhamento com Modelos de Dados 📚
Embora os DFDs se concentrem no fluxo, eles devem estar alinhados com Diagramas de Relacionamento de Entidades (ERD) ou modelos lógicos de dados. Os armazenamentos de dados no DFD devem corresponder às entidades no ERD.
- Verificação de Consistência: Se o DFD tiver um Armazenamento de Produto, o ERD deveria ter uma Produto entidade.
- Mapeamento de Atributos: Os atributos necessários pelo processo para interagir com o armazenamento devem existir no modelo de dados.
- Normalização: Embora os DFDs não imponham normalização, o projeto deve evitar redundâncias óbvias que sugiram um mau design de banco de dados.
Esse alinhamento garante que o design lógico (DFD) possa ser traduzido em implementação física (Esquema de Banco de Dados) sem rework significativo.
🔍 Lista de Verificação de Validação de Design 🔍
Antes de finalizar um Diagrama de Fluxo de Dados, use a seguinte lista de verificação para validar o design do armazenamento de dados.
| Princípio | Item da Lista de Verificação | Status |
|---|---|---|
| Nomenclatura | Todos os nomes de armazenamento são descritivos e consistentes? | ☐ |
| Conectividade | Cada armazenamento está conectado a pelo menos um processo? | ☐ |
| Direção do Fluxo | As setas estão apontando corretamente entre processos e armazenamentos? | ☐ |
| Rotulagem | Os dados estão fluindo através das linhas rotuladas com nomes de conteúdo? | ☐ |
| Sem Ligações Diretas entre Armazenamentos | Há alguma linha conectando diretamente Armazenamento a Armazenamento? | ☐ |
| Consistência | Os armazenamentos de nível inferior correspondem ao escopo do nível superior? | ☐ |
| Integridade | Todas as exigências de dados para os processos são atendidas pelos armazenamentos disponíveis? | ☐ |
🔄 Manutenção e Evolução 🔄
Os requisitos do sistema mudam. Os armazenamentos de dados devem ser adaptáveis a essas mudanças sem comprometer o modelo.
- Controle de Versão: Mantenha o controle das mudanças nas definições dos armazenamentos. Se um armazenamento for dividido, documente o caminho de migração.
- Dados Legados: Planeje como os dados antigos serão tratados quando o esquema de um armazenamento mudar. Isso frequentemente exige um armazenamento de arquivamento.
- Ciclo de Feedback: Use o feedback das equipes de desenvolvimento para aprimorar a granularidade dos armazenamentos. Se os desenvolvedores acharem um armazenamento muito amplo, divida-o. Se acharem muito fragmentado, unifique-o.
Um modelo estático é uma pendência. O design do armazenamento de dados deve ser revisado sempre que as regras de negócios mudarem ou forem introduzidas novas exigências de conformidade. Isso garante que o DFD permaneça um documento vivo que reflita com precisão as necessidades de dados do sistema.
📝 Conclusão sobre a Implementação
Projetar armazenamentos de dados em Diagramas de Fluxo de Dados é uma tarefa fundamental para a análise de sistemas. Ele fecha a lacuna entre processos abstratos e persistência concreta de dados. Ao seguir convenções rigorosas de nomeação, regras de conectividade e princípios de granularidade, os analistas criam modelos que são tanto legíveis quanto acionáveis.
O objetivo não é replicar perfeitamente o esquema do banco de dados, mas sim capturar a necessidade lógica do armazenamento de dados. Quando o DFD é preciso, a transição para o desenvolvimento é mais suave e o risco de perda de dados ou desalinhamento é significativamente reduzido. Foque na clareza, consistência e no fluxo lógico da informação para produzir projetos de sistemas de alta qualidade.