




В современной архитектуре программного обеспечения понимание того, как информация перемещается, столь же важно, как и понимание того, как она хранится. Диаграмма потоков данных (DFD) служит чертежом для этого перемещения, отображая путь данных от входа до выхода. При проектировании систем, предназначенных для роста, эти диаграммы трансформируются из простых набросков в сложные карты, определяющие производительность, надежность и поддерживаемость. В этом руководстве рассматриваются основные шаблоны, используемые для моделирования потоков данных в масштабируемых средах.
Масштабируемость — это не просто добавление дополнительных серверов; это перестройка способа перемещения данных по системе для предотвращения узких мест. Применяя конкретные шаблоны DFD, архитекторы могут визуализировать пределы пропускной способности до того, как они превратятся в проблемы в производственной среде. Такой подход гарантирует, что логический поток информации поддерживает как текущие требования, так и будущее расширение.
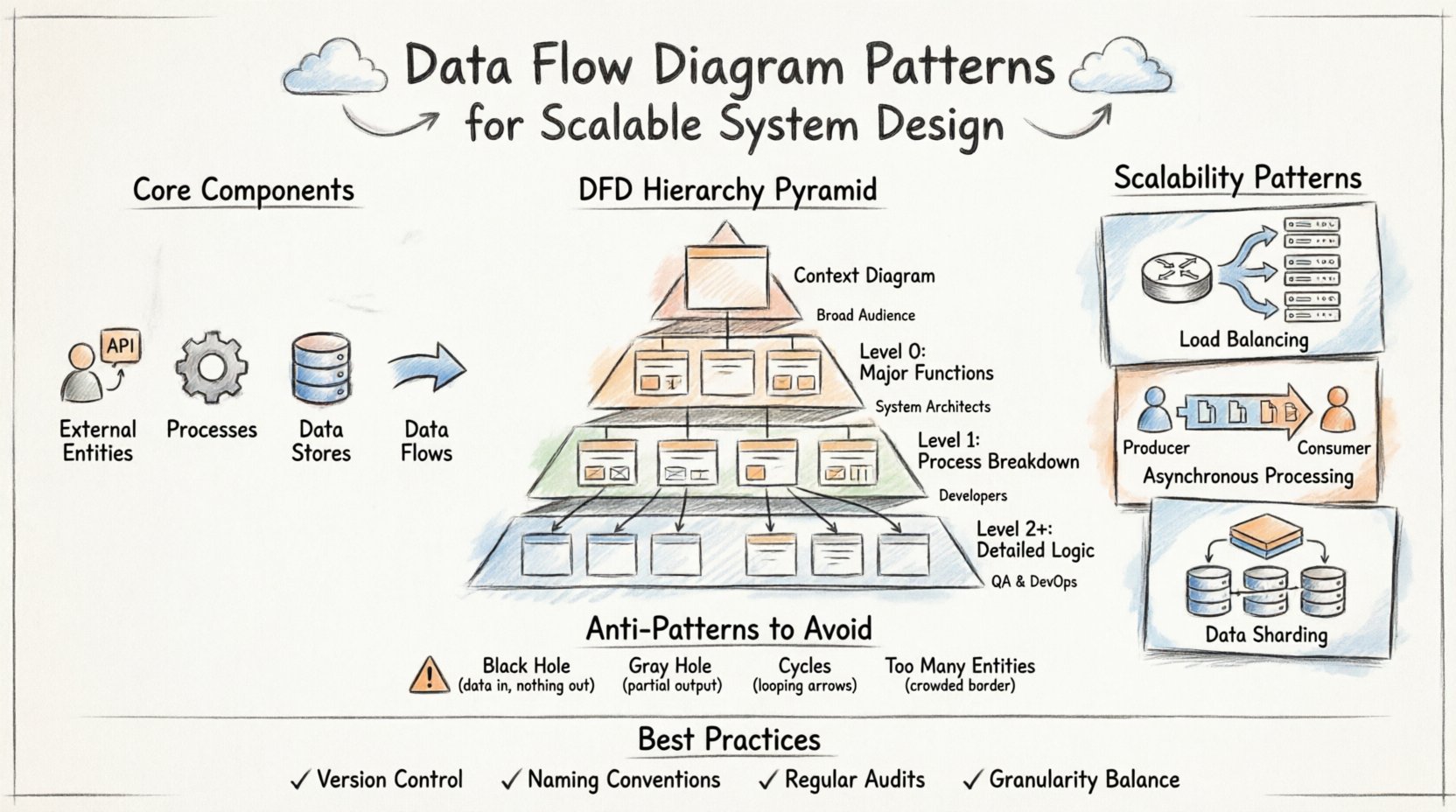
🧩 Основные компоненты диаграммы потоков данных
Прежде чем приступать к изучению шаблонов, необходимо освоить основные элементы. Каждая DFD опирается на четыре фундаментальных компонента. Их путаница приводит к неоднозначным моделям, которые неэффективно руководят разработкой.
- Внешние сущности: Представляют источники или пункты назначения за пределами границ системы. К ним относятся пользователи, сторонние API или аппаратные устройства.
- Процессы: Преобразуют данные из одной формы в другую. Это активные вычисления или точки бизнес-логики внутри системы.
- Хранилища данных: Места, где данные находятся в состоянии покоя. К ним могут относиться базы данных, файловые системы или кэши памяти.
- Потоки данных: Пути, по которым данные перемещаются между сущностями, процессами и хранилищами. Стрелки указывают направление и содержание.
Каждый компонент должен быть чётко определён, чтобы избежать неоднозначности. Например, процесс никогда не должен иметь стрелку, указывающую на другой процесс, без соответствующего потока данных. Каждая стрелка должна представлять фактическую информацию, перемещающуюся по системе.
📉 Иерархия уровней DFD
Масштабируемые системы требуют различных уровней абстракции. Одна диаграмма редко отражает всю сложность. Вместо этого используется иерархия, позволяющая спускаться от высокого уровня контекста до детальной логики реализации. Такая структура позволяет командам оценивать общую картину, не теряясь в деталях.
| Уровень | Фокус | Сложность | Основная аудитория |
|---|---|---|---|
| Диаграмма контекста | Границы системы и взаимодействия с внешними сущностями | Низкая | Заинтересованные стороны, руководство |
| Уровень 0 (DFD 0) | Основные функции системы и хранилища данных | Средняя | Архитекторы систем |
| Уровень 1 | Разбиение процессов уровня 0 | Высокий | Разработчики, инженеры |
| Уровень 2+ | Конкретная алгоритмическая или логика подпроцесса | Очень высокий | Специализированные инженеры |
Сохранение согласованности на этих уровнях имеет решающее значение. Хранилище данных, определённое на уровне 0, должно быть правильно ссылаться на уровне 1. Если процесс разделяется на уровне 1, входящие и исходящие потоки должны соответствовать родительскому процессу на уровне 0. Это равновесие обеспечивает надёжность модели на протяжении всего жизненного цикла.
🚀 Шаблоны масштабируемости в архитектуре системы
Проектирование с учётом масштабируемости требует определённых решений в моделировании. Стандартные диаграммы часто скрывают механизмы обработки нагрузки. Чтобы решить вопрос масштабируемости, архитекторы должны явно отображать шаблоны, распределяющие работу или управляющие ресурсами.
1. Балансировка нагрузки и распределение
В системах с высокой нагрузкой один процесс не может обрабатывать все входящие запросы. DFD должен отражать механизм распределения.
- Шаблон маршрутизатора: Введите узел процесса, который направляет трафик на несколько узлов сервисов.
- Репликация: Покажите несколько идентичных процессов, получающих один и тот же поток данных для параллельной обработки.
- Очереди: Представьте хранилище данных, которое выступает буфером до начала обработки, сглаживая пиковые нагрузки.
При рисовании маршрутизатора убедитесь, что поток разделяется логически. Если система использует стратегию циклического распределения, диаграмма должна указывать, что решение принимается на основе нагрузки, а не содержания данных. Это различие влияет на реализацию логики на стороне сервера.
2. Асинхронная обработка
Синхронные потоки могут создавать узкие места, если один шаг ожидает завершения другого. Асинхронные шаблоны разделяют процессы, позволяя системе масштабироваться независимо.
- Очереди сообщений: Используйте хранилище данных для представления очереди. Производитель записывает в хранилище, а потребитель читает из него позже.
- Потоки событий: Покажите процесс, генерирующий событие, которое запускает несколько потребителей вниз по потоку, не блокируя отправителя.
- Фоновые задачи: Разделяйте длительные задачи от запросов, ориентированных на пользователя, направляя их в выделенный пул процессов.
Это разделение позволяет процессам, ориентированным на пользователя, оставаться лёгкими, в то время как тяжёлая работа выполняется в фоновом режиме. DFD делает это разделение видимым, предотвращая упрощённое предположение о мгновенных ответах.
3. Разбиение данных и партиционирование
По мере роста объёма данных одиночные хранилища становятся барьерами производительности. Шаблоны разбиения данных на DFD помогают визуализировать, как данные разделяются между несколькими хранилищами.
- Горизонтальные разделения: Покажите процесс, перенаправляющий конкретные подмножества данных в различные хранилища данных на основе идентификатора или ключа.
- Реплики чтения: Укажите отдельные потоки для чтения данных с реплик, в то время как запись идет в основное хранилище.
- Уровни кэширования: Вставьте хранилище кэша между процессом и основной базой данных для снижения задержки.
| Шаблон | Преимущество масштабируемости | Компромисс |
|---|---|---|
| Балансировка нагрузки | Повышает пропускную способность | Увеличение сложности управления состоянием |
| Асинхронные очереди | Разъединяет зависимости | Потенциальная согласованность |
| Шардинг | Расширяет емкость хранения | Сложные запросы между шардами |
| Кэширование | Снижает задержку | Риски устаревания данных |
⚠️ Распространенные антишаблоны, которые следует избегать
Даже при хороших намерениях диаграммы потоков данных могут содержать структурные недостатки, приводящие к сбоям системы. Раннее распознавание этих антишаблонов предотвращает дорогостоящую рефакторизацию в будущем.
1. Чёрная дыра
Чёрная дыра возникает, когда процесс получает данные, но не выдаёт никакого выходного потока. Это часто происходит, когда предполагается, что процесс удаляет данные или обрабатывает их без уведомления.
- Риск:Потеря данных без уведомления об ошибке.
- Исправление: Убедитесь, что каждый вход имеет соответствующий выходной поток или чёткий путь ошибки.
- Влияние на масштабируемость:Незаметные сбои трудно отлаживать в распределённых системах.
2. Серая дыра
Серая дыра похожа на черную дыру, но с частичным выходом. Процесс потребляет больше данных, чем производит, но не объясняет, куда ушли остальные.
- Риск:Необъясненное потребление данных приводит к утечкам хранилища или ошибкам транзакций.
- Исправление:Явно моделируйте все пути данных, включая журналы ошибок или треки аудита.
3. Циклы в потоке данных
Хотя некоторые обратные связи необходимы (например, механизмы повторной попытки), неуправляемые циклы могут вызвать бесконечные циклы обработки.
- Риск:Зависание системы или исчерпание ресурсов.
- Исправление:Ограничьте глубину рекурсии на диаграмме и внедрите механизмы тайм-аута в архитектуре.
4. Бесконечные внешние сущности
Добавление слишком большого количества внешних сущностей делает диаграмму непонятной и затрудняет понимание основной логики.
- Риск:Потеря ясности границ системы.
- Исправление:Группируйте связанные сущности в одну сущность «Система хранения данных» или «Интерфейс пользователя», когда это уместно.
🔄 Лучшие практики для поддержки и эволюции
DFD — это не разовый продукт. Он должен развиваться вместе с ростом системы. Поддержание точности модели гарантирует, что новые члены команды поймут архитектуру без необходимости обратного проектирования кода.
- Контроль версий:Воспринимайте диаграммы как код. Храните их в репозитории для отслеживания изменений с течением времени.
- Соглашения об именовании:Используйте единые правила именования для процессов и потоков данных. «Обновить пользователя» всегда должно быть «Обновить пользователя», а не «Изменить данные пользователя».
- Регулярные аудиты:Планируйте периодические проверки, чтобы убедиться, что диаграмма соответствует текущей реализации.
- Баланс детализации:Не превращайте каждый процесс в подпроцесс. Группируйте связанную логику, чтобы сохранить управляемый обзор системы.
📝 Заключительные соображения
Эффективный дизайн системы зависит от ясной коммуникации. Диаграмма потоков данных предоставляет общую основу для архитекторов, разработчиков и заинтересованных сторон. Следуя установленным шаблонам и избегая распространённых ошибок, команды могут создавать системы, которые растут плавно.
Помните, что диаграммы — это модели, а не сама реальность. Они упрощают сложность, чтобы сделать её понятной. Однако упрощение не должно удалять критически важные детали, касающиеся целостности и потока данных. Когда ДФД точно отражает движение данных, он становится мощным инструментом для прогнозирования узких мест и оптимизации производительности.
По мере того как системы становятся более распределёнными, возрастает потребность в строгом моделировании. Описанные здесь шаблоны обеспечивают основу для такой строгости. Независимо от того, проектируете ли вы монолитное приложение или экосистему микросервисов, принципы потока данных остаются неизменными. Сосредоточьтесь на перемещении информации, и структура последует за этим.
Начните с диаграммы контекста. Чётко определите границы. Переходите к деталям процессов только тогда, когда это необходимо. Сохраняйте фокус на данных, а не на технологической стеке. Такая дисциплина гарантирует, что архитектура останется гибкой и масштабируемой на многие годы вперёд.