











Создание надежных системных моделей требует дисциплинированного подхода к тому, как информация захватывается, перемещается и сохраняется. В контексте диаграмм потоков данных (DFD) хранилище данных представляет собой основу системной устойчивости. Без четкого проектирования того, где хранятся данные, поток информации остается абстрактным и неприменимым. Данное руководство рассматривает основные принципы проектирования хранилищ данных в DFD, обеспечивая ясность, точность и соответствие архитектуре системы.
Эффективное моделирование выходит за рамки простого рисования линий между фигурами. Оно требует глубокого понимания целостности данных, паттернов доступа и жизненного цикла информации в системе. Следуя установленным принципам проектирования, аналитики могут создавать диаграммы, которые служат надежными чертежами для команд разработки.
🏷️ Определение хранилища данных 🏷️
Хранилище данных — это пассивный элемент в диаграмме потоков данных. В отличие от процессов, которые преобразуют данные, хранилища данных хранят данные в состоянии покоя. Они представляют файлы, базы данных, бумажные записи или любой другой репозиторий, где информация сохраняется для последующего извлечения.
- Пассивный характер:Данные не покидают хранилище, если процесс явно не запросит их.
- Идентичность хранилища:Это не процесс сам по себе; он не изменяет данные, он их хранит.
- Визуальное представление: Обычно изображается в виде прямоугольника с открытым концом или двойных вертикальных линий в зависимости от используемого стандарта нотации.
При проектировании этих элементов внимание должно фокусироваться на логических требованиях, а не на физической реализации. DFD описывает чтоданные, которые необходимы, а не какони физически индексируются или хранятся на жестком диске.
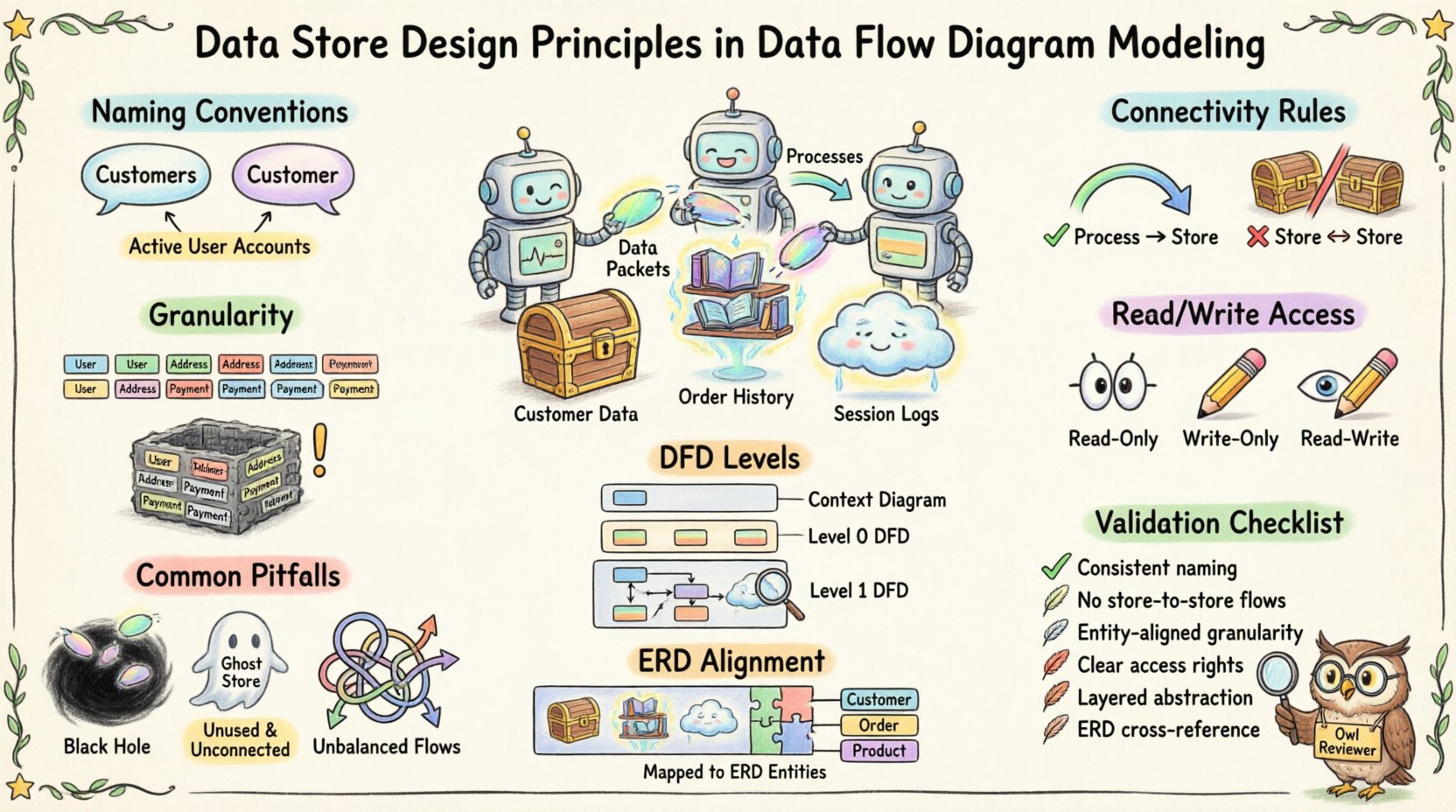
📝 Правила именования для ясности 📝
Именование — первый барьер против путаницы. Неоднозначные метки приводят к неверной интерпретации на этапе проектирования. Хорошо названное хранилище данных сразу дает контекст информации, которую оно содержит.
1. Единственное число против множественного числа
Согласованность — ключевое. Некоторые команды предпочитают единственное число (например, Клиент), в то время как другие используют множественное число (например, Клиенты). Критически важно, чтобы вся модель использовала одинаковую конвенцию.
- Рекомендация: Используйте множественное число для наборов данных (например, Заказы, Продукты) чтобы подчеркнуть, что это коллекция.
- Исключение:Единственное имя работает для конкретных экземпляров, если хранилище содержит только один тип записи (например, Конфигурация).
2. Описательная точность
Избегайте общих терминов, таких как Данные или Информация. Эти метки не дают никакого представления о содержимом.
- Плохой пример: Системные данные
- Хороший пример: Активные учетные записи пользователей
Конкретное наименование помогает заинтересованным сторонам сразу определить объем хранилища. Это снижает когнитивную нагрузку, необходимую для понимания диаграммы.
3. Время и состояние
Имена должны отражать состояние данных. Если хранилище содержит исторические записи, имя должно это отражать.
- Журналы транзакций означает запись о прошедших событиях.
- Ожидающие заказы означает данные, ожидающие действия.
🔗 Правила подключения 🔗
Передача данных в хранилище и из него регулируется строгими логическими правилами. Нарушение этих правил нарушает целостность DFD.
1. Требование подключения к процессу
Хранилище данных всегда должно быть подключено хотя бы к одному процессу. Оно не может существовать изолированно.
- Ввод: Процесс должен записывать данные в хранилище (например, сохранение новой записи).
- Вывод: Процесс должен читать данные из хранилища (например, извлечение записи).
Если хранилище не подключено ни к чему, оно является призрачным элементом без функции. Если оно подключено к нескольким процессам, поток данных для каждого подключения должен быть чётко определён.
2. Нет прямого потока данных между хранилищами
Данные не могут перемещаться непосредственно из одного хранилища данных в другое без промежуточного процесса. Это правило обеспечивает принцип, согласно которому преобразование или проверка данных происходят до их хранения.
- Неправильно: Линия, соединяющая Хранилище А непосредственно с Хранилище Б.
- Правильно: Процесс X читает из Хранилище А, преобразует данные и записывает в Хранилище Б.
Это разделение обеспечивает, что бизнес-логика, проверка или форматирование применяются до сохранения данных. Это предотвращает модель, которая может подразумевать, что данные просто копируются без контроля.
3. Метки потоков данных
Каждая линия, соединяющая процесс с хранилищем данных, должна быть помечена. Метка описывает конкретные данные, перемещающиеся через эту границу.
- Пример: Линия от Процесс заказов к Хранилище заказов может быть помечена как Сведения о заказе.
- Пример: Линия от Хранилище заказов к Процесс отчетности может быть помечен какИстория заказов.
Метки предоставляют контекст для объема и типа передаваемых данных. Они помогают разработчикам понять требования к схеме позже.
🎯 Уровень детализации и охват 🎯
Решение о том, как разделить данные на хранилища, является важным этапом проектирования. Слишком много хранилищ фрагментирует модель, а слишком мало создает монолитный блок информации.
1. Группировка по сущностям
Группируйте данные по логическим сущностям. Если система отслеживает клиентов, продукты и счета-фактуры, то они, как правило, должны находиться в отдельных хранилищах.
- Преимущество:Упрощает сопровождение. Изменения в данных о клиентах не влияют на логику хранения счетов-фактур.
- Преимущество:Снижает риск случайного повреждения данных во время обновлений.
2. Разделение чтения и записи
Рассмотрите, является ли хранилище в первую очередь для чтения или записи. Высокомасштабные журналы транзакций часто требуют иного подхода к хранению по сравнению с справочными данными.
- Справочные данные: Хранилища, такие какКоды стран являются преимущественно для чтения и редко изменяются.
- Данные транзакций: Хранилища, такие какЖурналы продаж являются преимущественно для записи и растут со временем.
Различение этих типов помогает в планировании емкости и шаблонов доступа, даже если DFD остается логической моделью.
3. Временное vs. Постоянное
Не все хранилища данных представляют постоянное хранение. Некоторые являются временными буферами.
- Данные сессии: Хранилища, используемые для временных пользовательских сессий во время процесса входа.
- Хранилища кэша: Временные места хранения для часто используемых данных.
Четкое обозначение временных хранилищ предотвращает путаницу в отношении политик хранения данных. Временное хранилище должно быть очищено после завершения процесса.
🔄 Поток данных и взаимодействие процессов 🔄
Связь между процессом и хранилищем данных является двунаправленной во многих случаях, но не всегда. Понимание направления потока данных необходимо для точного моделирования.
1. Доступ только для чтения
Некоторые хранилища доступны только для чтения. Процесс может запросить хранилище для отображения информации без её изменения.
- Пример: Процесс Отображение профиля процесс, читающий из Хранилище профиля пользователя.
- Ограничение:Стрелка потока данных не должна указывать от хранилища к процессу и обратно в рамках одной и той же транзакции, если это не подразумевает операцию записи.
2. Доступ только для записи
Некоторые процессы записывают данные, не требуя их предварительного извлечения.
- Пример: Процесс Журнал событий процесс, записывающий в Хранилище системного аудита.
- Ограничение: Убедитесь, что процесс обладает необходимым контекстом для правильной записи данных без внешнего ввода.
3. Доступ для чтения и записи
Большинство бизнес-процессов включают извлечение, изменение и сохранение данных.
- Пример: Обновление инвентаря читает текущий остаток, рассчитывает новую сумму и сохраняет её.
- Моделирование: Используйте отдельные потоки для чтения и записи, чтобы уточнить последовательность операций.
Это различие помогает разработчикам понять, требуется ли блокировка или немедленная фиксация транзакции базы данных.
📊 Уровни потоков данных и видимость хранилищ данных 📊
Схемы потоков данных часто разбиваются на уровни — от диаграмм контекста (уровень 0) до детализированных разборов (уровень 2, уровень 3). Хранилища данных выглядят по-разному на каждом уровне.
1. Уровень контекста (уровень 0)
На самом высоком уровне хранилища данных часто опускаются для сохранения простоты. Основное внимание уделяется внешним сущностям и основному границе системы.
- Причина:Слишком много деталей затрудняет понимание обмена данными на высоком уровне.
- Исключение:Основные внешние базы данных могут быть показаны, если они критически важны для границы системы.
2. Разбиение на уровень 1
По мере разбиения системы на основные процессы хранилища данных становятся видимыми. Именно здесь определяется основная архитектура хранения данных.
- Фокус:Определите основные хранилища, необходимые для каждой основной функции.
- Детали:Убедитесь, что каждый процесс имеет место назначения для своих выходных данных.
3. Уровень 2 и выше
Дальнейшее разбиение может разделить крупные хранилища данных на более мелкие и специфические.
- Пример: Хранилище клиентов на уровне 1 может быть разделено на Хранилище контактной информации и Хранилище выставления счетов на уровне 2.
- Согласованность:Убедитесь, что данные на нижних уровнях соответствуют данным на более высоких уровнях. Не вводите новые типы данных, которых не было на родительской диаграмме.
⚠️ Распространённые ошибки ⚠️
Даже опытные аналитики допускают ошибки при проектировании хранилищ данных. Избегание этих распространённых ошибок обеспечивает точность диаграммы.
- Чёрные дыры:Процесс, который принимает данные, но не записывает их ни в одно место. Это означает потерю данных.
- Огненные штормы: Процесс, который принимает данные, но создает выходные данные без хранилища. Это означает, что данные создаются из ничего (чудо).
- Призрачные хранилища: Хранилища данных без подключенных процессов. Это тупиковые точки.
- Несбалансированные потоки: При переходе с уровня 1 на уровень 2 входы и выходы должны соответствовать. Если в уровне 2 добавляется хранилище, оно должно быть обосновано входами/выходами родительского процесса.
- Чрезмерная детализация: Попытка моделировать каждую таблицу базы данных как отдельное хранилище на диаграмме уровня 1. Остаётесь на уровне логических сущностей, а не физических таблиц.
📚 Согласование с моделями данных 📚
Хотя ДФД фокусируются на потоках, они должны соответствовать диаграммам связей сущностей (ERD) или логическим моделям данных. Хранилища данных в ДФД должны соответствовать сущностям в ERD.
- Проверка согласованности: Если ДФД содержитхранилище продуктов, то ERD должен содержатьсущность «Продукт»сущность.
- Сопоставление атрибутов: Атрибуты, необходимые процессу для взаимодействия с хранилищем, должны существовать в модели данных.
- Нормализация: Хотя ДФД не накладывают нормализацию, дизайн должен избегать очевидной избыточности, указывающей на плохой дизайн базы данных.
Это согласование обеспечивает, что логический дизайн (ДФД) может быть преобразован в физическую реализацию (схема базы данных) без значительной переделки.
🔍 Чек-лист проверки проектирования 🔍
Перед окончательным утверждением диаграммы потоков данных используйте следующий чек-лист для проверки проектирования хранилищ данных.
| Принцип | Пункт чек-листа | Статус |
|---|---|---|
| Именование | Все имена хранилищ описательны и согласованы? | ☐ |
| Связность | Подключен ли каждый магазин хотя бы к одному процессу? | ☐ |
| Направление потока | Стрелки правильно направлены между процессами и магазинами? | ☐ |
| Метки | Данные протекают по линиям, помеченным именами содержимого? | ☐ |
| Нет прямых связей между магазинами | Есть ли какие-либо линии, напрямую соединяющие магазин с магазином? | ☐ |
| Согласованность | Соответствуют ли магазины нижнего уровня масштабу родительского уровня? | ☐ |
| Целостность | Все требования к данным для процессов удовлетворяются доступными магазинами? | ☐ |
🔄 Обслуживание и эволюция 🔄
Требования к системе меняются. Магазины данных должны быть адаптивными к этим изменениям без нарушения модели.
- Контроль версий: Ведите учёт изменений в определениях магазинов. Если магазин разделяется, зафиксируйте путь миграции.
- Устаревшие данные: Планируйте, как будут обрабатываться старые данные при изменении схемы магазина. Часто это требует архивного магазина.
- Петля обратной связи: Используйте обратную связь от команд разработки для уточнения детализации магазинов. Если разработчики считают магазин слишком широким, разделите его. Если они считают его слишком фрагментированным, объедините его.
Статическая модель — это риск. Проектирование магазинов данных должно пересматриваться каждый раз, когда меняются бизнес-правила или вводятся новые требования к соблюдению. Это гарантирует, что ДФД остаётся живым документом, точно отражающим потребности системы в данных.
📝 Заключение по реализации
Проектирование магазинов данных в диаграммах потоков данных — фундаментальная задача системного анализа. Оно устраняет разрыв между абстрактными процессами и конкретным хранением данных. Следуя строгим правилам именования, правилам подключения и принципам детализации, аналитики создают модели, которые одновременно понятны и применимы.
Цель заключается не в том, чтобы идеально воспроизвести схему базы данных, а в том, чтобы зафиксировать логическую необходимость хранения данных. Когда ДФД точна, переход к разработке становится более плавным, а риск потери данных или несоответствия значительно снижается. Сосредоточьтесь на ясности, согласованности и логическом потоке информации, чтобы создавать высококачественные системы.