








准确的项目估算构成了软件开发成功的关键。在规划系统时,理解底层的数据流动为预测资源需求提供了坚实的基础。数据流图(DFD)作为一种强大的可视化工具,可用于描绘这些数据流动。通过分析DFD的结构复杂性,团队能够得出比仅依赖功能需求更可靠的工时估算。
本指南探讨如何利用DFD复杂性度量来优化工作量估算。我们将分析推动复杂性的各个要素,量化这些要素的方法,以及如何将图示分析转化为项目时间表的过程。
🔍 在规划中理解数据流图
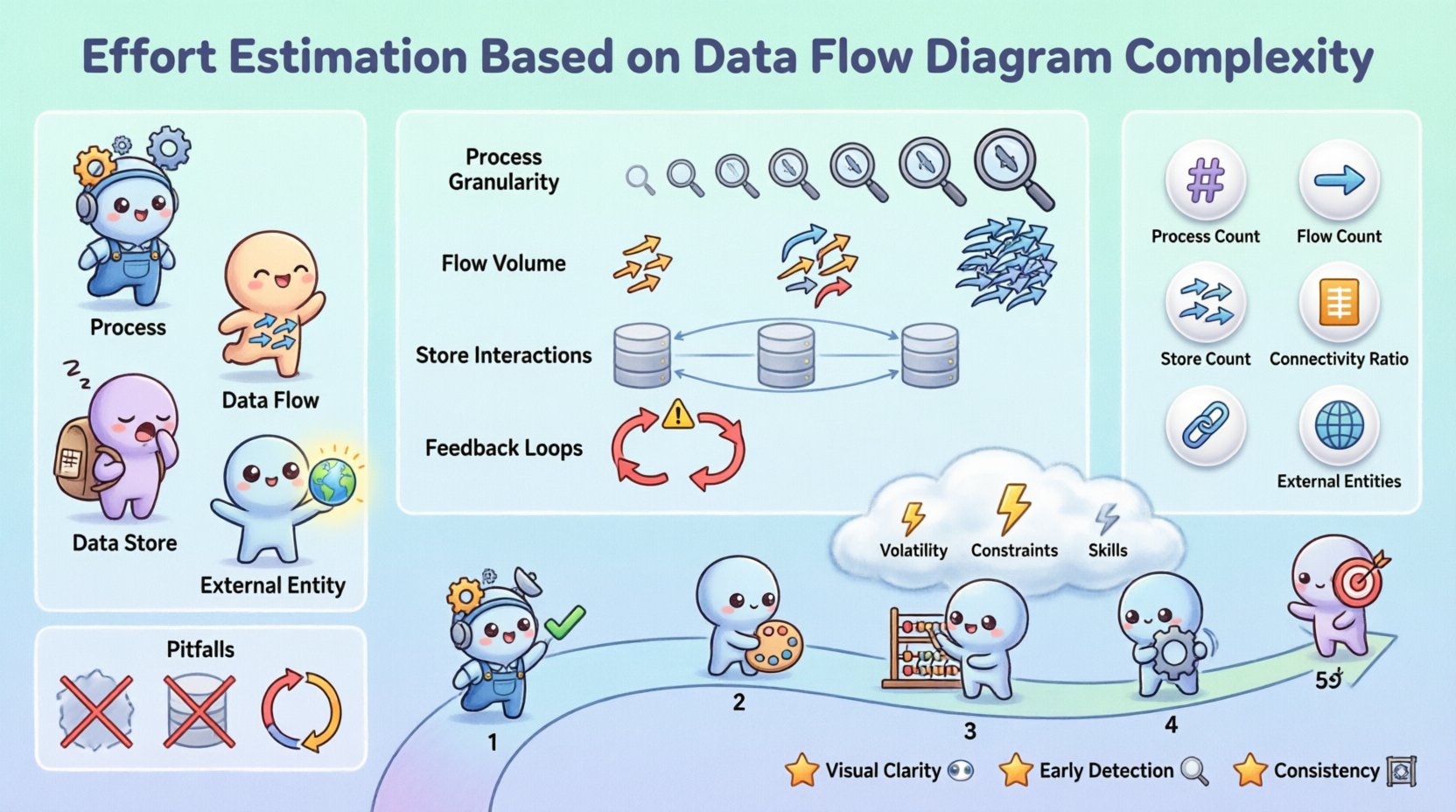
数据流图是信息系统中数据流动的图形化表示。与侧重于控制逻辑的流程图不同,DFD侧重于数据转换。在估算的背景下,DFD充当了相关工作的蓝图。
- 处理过程: 表示数据的转换。每个处理过程通常对应代码中的一个特定功能或模块。
- 数据流: 显示数据在处理过程、存储和实体之间的流动。这些代表了接口和集成点。
- 数据存储: 标识数据静止存放的位置。这些对应于数据库表或文件系统。
- 外部实体: 系统外部的数据来源或目的地。这些定义了集成需求。
在估算工作量时,这些要素的视觉密度和连接性提供了关于实现系统所需认知负荷的线索。结构稀疏且流程线性的图示表明复杂性较低,而密集的交互网络则暗示着重大的集成挑战。
🏗️ 识别复杂性驱动因素
并非所有数据流都具有相同的复杂性。有些仅表示简单的字段传输,而另一些则涉及复杂的业务逻辑、验证或安全协议。为了准确估算,必须识别出图中增加复杂性的具体驱动因素。
1. 处理粒度
处理的详细程度至关重要。一个高层次的处理过程,如“处理订单”,可能隐藏着数十个子步骤。如果DFD处于高层次,估算必须考虑该过程的分解。相反,详细程度较高的第2级或第3级DFD则揭示了实际的工作单元。
- 粗粒度处理过程: 需要更多分析时间进行分解。
- 细粒度处理过程: 可以进行更直接的估算,但可能忽略集成开销。
2. 数据流数量
连接元素的箭头数量反映了数据处理的规模。每个箭头代表一个必须经过验证、转换,并存储或传输的数据结构。
- 更多的数据流通常意味着更多的API端点或数据库查询。
- 复杂的流可能需要错误处理和重试逻辑。
3. 数据存储交互
每次与数据存储的交互都会引入延迟考量、并发问题和模式管理。一个同时读写多个存储的处理过程,比仅与单一存储交互的处理过程更为复杂。
4. 反馈回路
图中的回路表示迭代处理或状态变化。这些通常是开发中最容易出错的区域。估算回路时,需要考虑在多个周期中保持状态的测试场景。
📏 估算的定量指标
为了从定性观察转向定量估算,可以应用从DFD中得出的特定指标。这些指标有助于在不同项目间标准化估算过程。
| 指标 | 描述 | 对工作量的影响 |
|---|---|---|
| 过程数量 | 转换节点的总数。 | 与功能点直接相关。 |
| 流数量 | 数据流动箭头的总数。 | 表明集成和接口的复杂性。 |
| 存储数量 | 数据存储库的总数。 | 影响数据库设计和迁移工作量。 |
| 连接度比率 | 流与过程的比率。 | 高比率表明系统耦合紧密。 |
| 外部实体数量 | 涉及的外部系统数量。 | 增加沟通和依赖风险。 |
通过将这些数值相加,可以创建一个复杂度评分。例如,一个简单系统可能有5个过程和10个流,而一个复杂系统可能有50个过程和150个流。然后,该评分可以乘以根据历史数据确定的基准工作量系数。
🛠️ 估算过程
将DFD转化为工作量估算需要采用结构化的方法。遵循以下步骤,以确保规划的一致性和准确性。
步骤1:验证图表完整性
在估算之前,请确保DFD准确反映了需求。缺失的流或实体会导致估算偏低。请检查每个数据需求是否都有对应的流,且每个过程都有明确的输入和输出。
步骤2:分类过程复杂度
并非所有过程都需要相同的工作量。根据其逻辑为每个过程分配复杂度权重。
- 简单:直接的数据映射或检索。(权重:1)
- 中等: 包括验证、计算或格式化。(权重:2)
- 复杂: 涉及多个数据存储、外部API或复杂算法。(权重:3)
步骤3:计算基础工作量
将每个类别中的过程数量乘以其相应的权重,将这些值相加,得到基础复杂度得分(BCS)。
公式: BCS =(简单数量 × 1)+(中等数量 × 2)+(复杂数量 × 3)
步骤4:根据流复杂度进行调整
大量数据流动会增加接口开发所需的工作量。根据总流数量与过程数量的比值,应用流倍数进行调整。
- 低比率(每过程≤2个流): 倍数 1.0
- 中等比率(每过程3-5个流): 倍数 1.2
- 高比率(每过程>5个流): 倍数 1.5
步骤5:考虑外部依赖
外部实体会引入风险。每个外部系统都需要集成测试、安全配置以及潜在的供应商协调。为每个外部实体增加固定的时间缓冲。
⚠️ 考虑风险与不确定性
即使拥有详细的DFD,不确定性依然存在。需求变更或技术债务等因素可能改变所需工作量。应调整估算以应对这些风险。
1. 需求波动性
如果业务需求在开发过程中可能发生变更,DFD可能需要大幅修改。在这种情况下,应在总工作量上增加15-20%的应急缓冲。
2. 技术限制
遗留系统或特定基础设施要求可能使数据流变得复杂。如果DFD显示数据流向遗留主机,处理该连接的工作量可能高于标准API调用。
3. 团队技能水平
估算假设具备基本能力。如果团队对领域或技术栈不熟悉,DFD流程的复杂性可能转化为更多学习时间。应相应调整每个过程单位的时间。
🚫 DFD分析中的常见陷阱
避免常见错误对于保持估算的准确性至关重要。一些陷阱可能导致重大估算偏差。
- 忽略数据验证: DFD显示数据流动,但未体现其应用的规则。验证逻辑通常占过程工作量的20-30%。
- 忽视错误处理: 正常路径很容易绘制。错误路径、重试和日志记录会为每个流程增加隐藏的复杂性。
- 假设线性增长: 复杂性通常呈非线性增长。由于需要保证事务一致性,增加一个数据存储可能会使连接复杂性呈指数级增长。
- 忽视安全: 加密、身份验证和授权层在数据流图中往往是隐含的。在估算时必须明确考虑这些因素。
- 仅关注流程: 数据存储和数据流通常比流程本身更耗时,设置和测试起来也更复杂。
📅 将估算结果整合到项目计划中
一旦工作量计算完成,就必须将其映射到时间表上。这包括资源分配和里程碑定义。
- 分阶段交付: 根据数据流依赖关系对流程进行分组。优先交付高优先级的数据流,以降低风险。
- 并行工作流: 如果流程相互独立,就可以并行开发。利用数据流图识别出独立的模块群。
- 集成测试: 安排专门时间来测试数据流的完整性。这往往是复杂数据流图失效的地方。
通过将时间表与图中所示的结构依赖关系对齐,可以创建一个符合系统自然流程的现实时间线。
🔄 长期保持准确性
估算并非一成不变。随着项目推进和数据流图的演变,估算应随之重新校准。
- 基线更新: 当数据流图最终确定后,用实际的复杂度评分更新初始估算。
- 回顾分析: 每个阶段结束后,将估算的复杂度评分与实际投入的工作量进行对比。这有助于优化未来项目的权重因子。
- 变更管理: 对数据流图的任何更改都应触发重新估算。不要认为增加一个小型数据流的影响可以忽略不计。
🛡️ 基于数据流图规划的最终考量
使用数据流图进行工作量估算,提供了一种结构化且客观的方法来评估项目规模。它使讨论从猜测转向对系统实际数据架构的分析。
尽管没有模型是完美的,但数据流图复杂度方法具有显著优势:
- 可视化清晰度: 利益相关者可以直观看到数据的流动,使工作量的合理性变得透明。
- 早期发现:可以在编码开始之前识别复杂流程,从而进行架构调整。
- 一致性:在不同项目中应用相同的度量标准,有助于更好地进行投资组合管理。
请记住,目标不是完美,而是有依据的规划。定期审查您的复杂度因素并更新基准。随着团队对特定类型流程和过程的经验积累,您预测工作量的能力将自然提升。
通过将DFD作为主要估算工具,您可以使规划与所构建系统的根本特性保持一致。这将带来更现实的预算、更合理的进度安排,最终实现更成功的软件解决方案交付。