











设计一个稳健的微服务架构,远不止将代码拆分成更小的部分。它需要清晰地理解信息在系统中的流动方式。如果没有结构化的方法,分布式系统往往会演变成难以维护和扩展的复杂依赖网络。这时,数据流图(DFD)就成为架构师不可或缺的工具。通过可视化数据的流动,团队可以精准地定义服务边界,并确保平台内底层数据逻辑的一致性。
本指南探讨了在微服务实施规划阶段如何利用DFD。我们将研究图表的层级结构、关键边界的识别,以及数据所有权管理的策略。目标是提供一个系统化的方法框架,以确保系统设计的清晰性和可维护性。
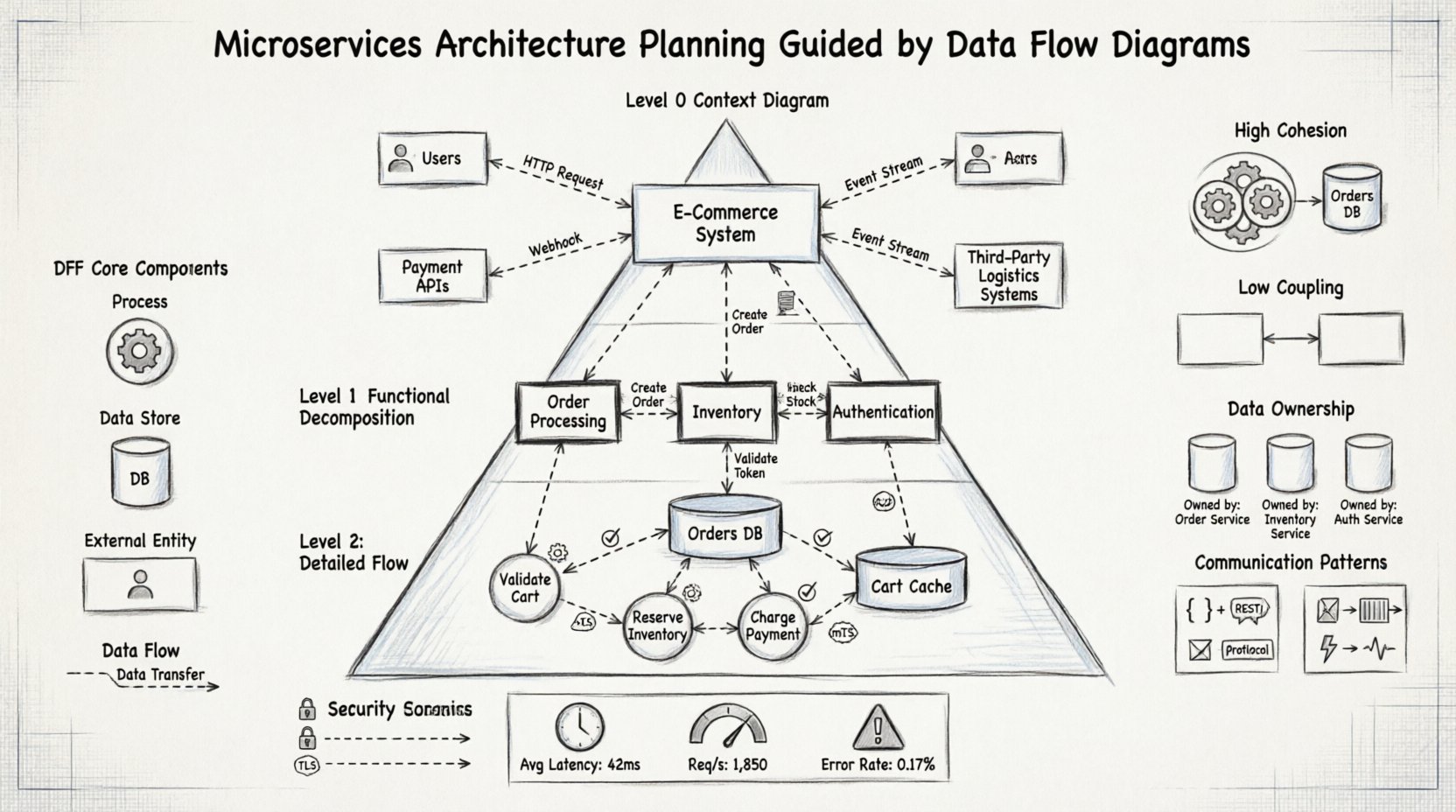
🧩 理解DFD在分布式系统中的作用
数据流图(DFD)表示信息在系统中的流动过程。与侧重于控制流和决策逻辑的流程图不同,DFD强调的是数据的转换和存储。在微服务的背景下,这种区别至关重要。微服务本质上是独立的处理单元,它们之间交换数据。通过可视化这种交换,利益相关者能够更好地理解变更的影响。
DFD的核心组成部分
在将DFD应用于架构之前,必须先理解所使用的基础符号:
- 处理过程:表示数据的转换。在微服务中,这些通常对应于特定的服务功能或API。
- 数据存储:数据静止存放的位置。这些对应于数据库、缓存或文件系统。
- 外部实体:系统外部的数据来源或目的地。包括用户、第三方系统或遗留应用程序。
- 数据流:在处理过程、存储和实体之间流动的数据。它们代表了服务之间的网络流量或消息队列。
📊 规划图表的层级结构
一个全面的架构规划需要多个抽象层次。从高层次概览开始,逐步深入到具体细节,可以确保不会遗漏任何关键的数据路径。这种分层方法与微服务的分层设计天然契合。
第0层:上下文图
第0层图,通常称为上下文图,提供了最宏观的视角。它将整个系统表示为一个单一的处理过程,并标识出所有与之交互的外部实体。这是规划的第一步,因为它定义了系统的范围。
- 识别边界:明确标出系统内部和外部的内容。
- 外部接口:列出数据进入和离开系统的每一个接口点。
- 主要输入/输出:确定系统的主数据触发源。
对于微服务而言,这一层级有助于回答问题:“系统为用户做了什么?”它为后续的分解奠定了基础。
第1层:主要功能分解
在确立上下文后,单一的处理过程被分解为多个主要子过程。在微服务的背景下,这些子过程往往暗示了最初的微服务候选者。这一层级将系统分解为逻辑域。
- 领域对齐:按业务能力对处理过程进行分组(例如,订单处理、库存管理、用户认证)。
- 服务候选:每个主要流程都可能成为一个潜在的微服务。
- 服务间通信:识别这些主要领域之间的数据流。
第二级:详细流分析
最详细的层级聚焦于服务内部的具体功能。在这里,数据验证、转换和存储逻辑被映射出来。这确保了在开始实施之前,服务的内部逻辑是连贯的。
🏗️ 将数据流映射到服务边界
微服务架构中最关键的挑战之一是定义服务边界。如果边界划分不当,服务之间会变得高度耦合,从而导致“分布式单体”反模式。DFD通过突出显示数据依赖关系,有助于划定这些边界。
识别内聚性
服务应具有高内聚性,即服务内的所有功能都紧密协作于特定的数据集。DFD通过将共享相同数据存储和数据流的流程分组,帮助可视化这一点。
- 分组流程:如果流程A和流程B总是直接交换数据而无需外部触发,它们很可能属于同一个服务。
- 共享数据存储:访问同一数据存储的流程应被评估是否具有合并的潜力。
最小化耦合
耦合指的是服务之间相互依赖的程度。DFD通过显示有多少数据流跨越了所提议的边界来揭示耦合情况。目标是尽量减少跨越服务边界的请求数量。
- 直接连接:减少服务之间的直接数据流数量。
- 间接连接:优先采用异步消息传递或事件驱动架构,以解耦服务。
🗄️ 管理数据所有权与一致性
在单体数据库中,数据一致性通过事务来处理。在微服务中,每个服务通常拥有自己的数据。DFD在明确所有权方面起着关键作用。通过将数据流映射到数据存储,架构师可以将所有权分配给特定的流程。
每个服务一个数据库模式
每个微服务应管理其自己的数据存储。DFD通过追踪数据的来源和消费位置,帮助识别哪些数据属于哪个服务。
- 数据源:写入数据的流程拥有该数据存储。
- 读取访问:其他流程可以通过定义好的数据流(API)读取数据,但不能直接修改它。
一致性模型
分布式系统通常依赖最终一致性而非即时一致性。DFD突出了哪些地方需要强一致性,哪些地方可以放宽要求。
- 强一致性: 用于金融交易或库存更新。这些流程标记为同步。
- 最终一致性: 用户资料或日志记录可接受。这些流程通常是异步的。
🔗 通信模式与集成
服务定义后,架构必须明确它们之间的通信方式。DFD区分不同类型的数据流,这有助于选择通信技术。
请求-应答 vs. 事件驱动
并非所有数据流都需要立即响应。DFD有助于根据其时间要求对流程进行分类。
- 同步流程: 当下游流程需要立即获取数据才能继续时使用。这些通常映射到 REST 或 gRPC API。
- 异步流程: 用于后台处理或通知。这些映射到消息队列或事件总线。
⚠️ 基于DFD规划的常见陷阱
尽管DFD功能强大,但如果使用不当,容易产生误解。架构师应警惕可能阻碍规划过程的常见错误。
陷阱1:上下文过度详细
在上下文层级一开始就包含过多细节,会掩盖高层次视图。保持第0层简单。只有在进入第1层和第2层时才增加复杂性。
陷阱2:忽略非功能性需求
DFD关注数据,而非性能或安全。在映射流程时,应考虑延迟要求和安全边界。某个数据流可能在技术上可行,但违反安全策略。
陷阱3:循环依赖
DFD可以揭示循环数据流,例如服务A调用服务B,而服务B又调用服务A。这会导致死锁或无限循环。必须通过重新调整数据所有权来打破这些循环。
📋 DFD层级的对比分析
为了更好地理解DFD层级如何对应架构决策,请参考下面的表格。
| DFD层级 | 关注领域 | 架构输出 |
|---|---|---|
| 上下文(第0层) | 系统范围 | 服务边界定义 |
| 功能(第1层) | 主要领域 | 服务目录与API合约 |
| 逻辑(第2级) | 内部逻辑 | 数据模型与验证规则 |
| 物理 | 基础设施 | 部署拓扑与网络配置 |
🔄 迭代优化与维护
架构不是一次性事件。随着业务的发展,数据流会发生变化。DFD作为动态文档,应与代码库同步更新。
版本化图表
正如API需要版本化一样,DFD也应进行版本化,以追踪随时间推移的架构变更。这有助于团队理解过去为何做出某些决策。
- 变更日志:记录对每个数据流或流程的每一次修改。
- 影响分析:利用图表评估一个服务的变更对其他服务的影响。
自动化验证
虽然手动图表很有用,但自动化验证可以确保实现与设计一致。工具可以验证实际网络流量是否与DFD中定义的流程相符。
🛡️ 数据流中的安全考量
安全常常在设计中被忽视,但DFD可以让安全从一开始就融入其中。每个数据流都代表一个潜在的攻击面。
定义信任区域
标记图表中需要不同安全级别的区域。内部流可能被信任,而外部流则需要加密和身份验证。
- 外部流: 需要TLS、API密钥或OAuth令牌。
- 内部流: 需要双向TLS或服务间身份验证。
数据分类
根据敏感程度对数据流进行标记。敏感数据(个人身份信息、财务信息)需要比公开数据更严格的控制。
- 高敏感度: 静态和传输中均对数据进行加密。
- 低敏感度: 标准加密协议已足够。
📈 使用数据流图衡量成功
你怎么知道架构是否在正常运行?数据流图提供了衡量的基准。通过将实际的数据流动与计划的图表进行对比,团队可以识别出瓶颈。
性能指标
- 延迟: 测量数据通过流程所花费的时间。
- 吞吐量: 测量在流程之间移动的数据量。
- 错误率: 识别那些频繁失败的流程。
优化机会
数据流图突出了冗余路径。如果两个服务反复交换相同的数据,可以引入缓存层或共享读取模型来优化性能。
🚀 战略规划的结论
使用数据流图进行微服务规划,将重点从代码转移到信息上。这确保了架构支持业务逻辑,而不是反过来。通过遵循结构化的数据流图方法,团队可以构建出模块化、可维护且可扩展的系统。
这一过程需要纪律。它要求架构师抵制过早过度优化的冲动,转而专注于明确的边界和数据所有权。当数据流图准确时,实现过程就会自然跟进。这种方法减少了技术债务,为长期发展奠定了基础。
请记住,图表既是设计工具,也是沟通工具。它弥合了技术团队与业务利益相关者之间的差距。当每个人都理解数据的流动方式时,整个组织就能就系统的能力和限制做出更好的决策。