




In der modernen Softwarearchitektur ist das Verständnis dafür, wie Informationen sich bewegen, ebenso entscheidend wie das Verständnis dafür, wie sie gespeichert werden. Ein Datenflussdiagramm (DFD) dient als Bauplan für diese Bewegung und zeigt die Reise der Daten von der Eingabe bis zur Ausgabe auf. Bei der Gestaltung von Systemen, die Wachstum bewältigen sollen, entwickeln sich diese Diagramme von einfachen Skizzen zu komplexen Karten, die Leistungsfähigkeit, Zuverlässigkeit und Wartbarkeit bestimmen. Dieser Leitfaden untersucht die wesentlichen Muster, die zur Modellierung von Datenflüssen in skalierbaren Umgebungen verwendet werden.
Skalierbarkeit geht nicht nur darum, mehr Server hinzuzufügen; es geht vielmehr darum, die Art und Weise, wie Daten durch das System fließen, neu zu strukturieren, um Engpässe zu vermeiden. Durch die Anwendung spezifischer DFD-Muster können Architekten Kapazitätsgrenzen visualisieren, bevor sie zu Produktionsproblemen werden. Dieser Ansatz stellt sicher, dass der logische Informationsfluss sowohl den aktuellen Anforderungen als auch zukünftigen Erweiterungen gerecht wird.
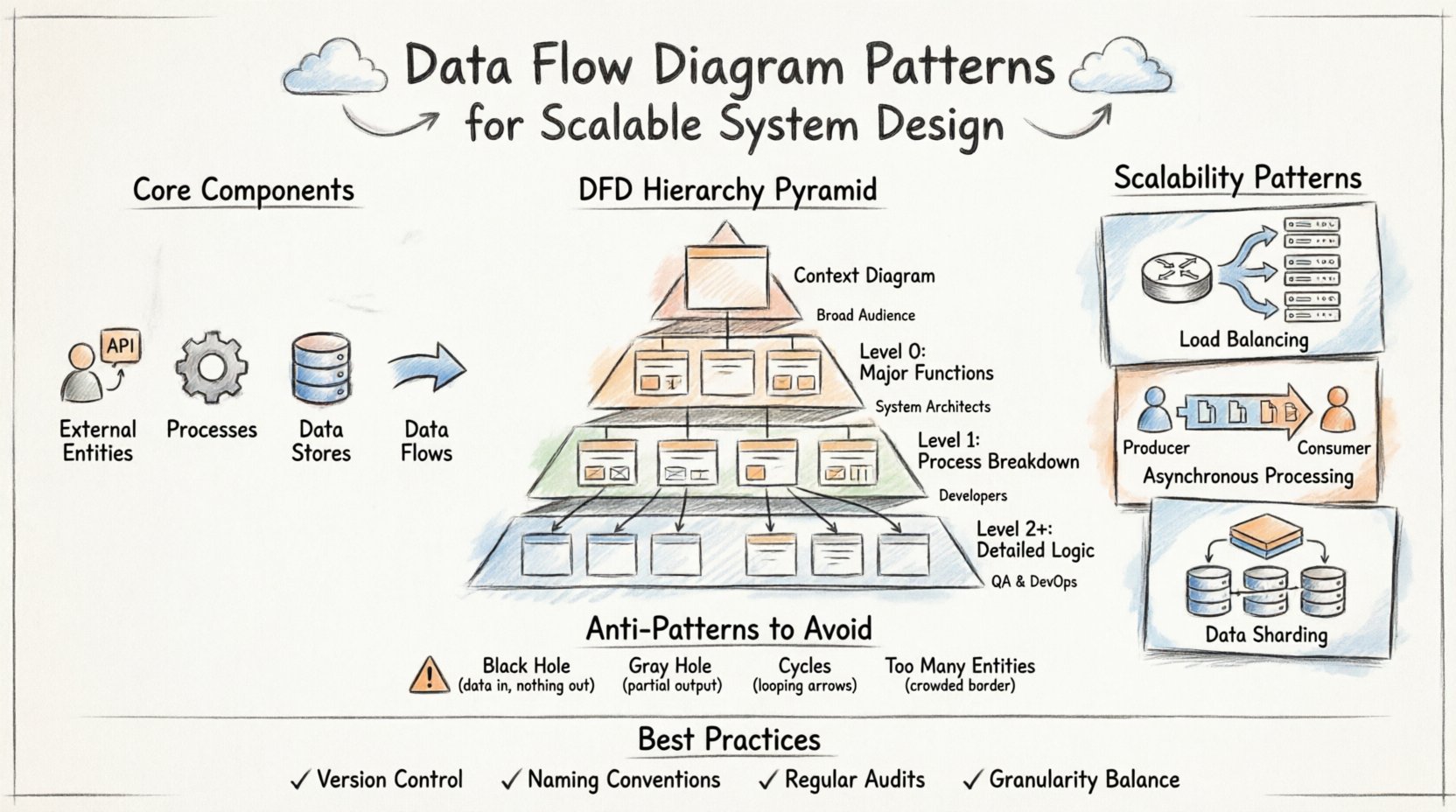
🧩 Kernkomponenten eines Datenflussdiagramms
Bevor man sich mit Mustern beschäftigt, muss man die Bausteine beherrschen. Jedes DFD beruht auf vier grundlegenden Elementen. Die Verwechslung dieser führt zu mehrdeutigen Modellen, die die Entwicklung nicht effektiv leiten können.
- Externe Entitäten: Stellen Quellen oder Ziele außerhalb der Systemgrenze dar. Dazu gehören Benutzer, Drittanbieter-APIs oder Hardwaregeräte.
- Prozesse: Wandeln Daten von einer Form in eine andere um. Es handelt sich um die aktiven Berechnungen oder Punkte des Geschäftslogik innerhalb des Systems.
- Datenbanken: Orte, an denen Daten ruhen. Dazu können Datenbanken, Dateisysteme oder Speicher-Caches gehören.
- Datenflüsse: Die Wege, die Daten zwischen Entitäten, Prozessen und Speichern nehmen. Pfeile zeigen Richtung und Inhalt an.
Jedes Komponente muss klar definiert sein, um Mehrdeutigkeiten zu vermeiden. Ein Prozess sollte beispielsweise niemals einen Pfeil zu einem anderen Prozess haben, ohne dass ein entsprechender Datenfluss vorhanden ist. Jeder Pfeil muss tatsächliche Informationen darstellen, die durch das System fließen.
📉 Die Hierarchie der DFD-Ebenen
Skalierbare Systeme erfordern unterschiedliche Abstraktionsstufen. Ein einzelnes Diagramm erfasst selten die gesamte Komplexität. Stattdessen wird eine Hierarchie verwendet, um von der übergeordneten Betrachtung bis zur detaillierten Implementierungslogik vorzudringen. Diese Struktur ermöglicht es Teams, das Gesamtbild zu überprüfen, ohne sich im Detail zu verlieren.
| Ebene | Schwerpunkt | Komplexität | Primäre Zielgruppe |
|---|---|---|---|
| Kontextdiagramm | Systemgrenze und externe Interaktionen | Niedrig | Interessenten, Management |
| Ebene 0 (DFD 0) | Wichtige Systemfunktionen und Datenbanken | Mittel | Systemarchitekten |
| Ebene 1 | Aufgliederung der Prozesse der Ebene 0 | Hoch | Entwickler, Ingenieure |
| Ebene 2+ | Spezifische algorithmische oder Unterprozess-Logik | Sehr hoch | Spezialisierte Ingenieure |
Die Aufrechterhaltung der Konsistenz über diese Ebenen hinweg ist entscheidend. Ein in Ebene 0 identifizierter Datenspeicher muss in Ebene 1 korrekt referenziert werden. Wenn ein Prozess in Ebene 1 aufgeteilt wird, müssen die Eingangs- und Ausgangsströme mit dem übergeordneten Prozess in Ebene 0 übereinstimmen. Diese Balance stellt sicher, dass das Modell während des gesamten Lebenszyklus eine zuverlässige Referenz bleibt.
🚀 Skalierbarkeitsmuster in der Systemarchitektur
Das Gestalten für Skalierbarkeit erfordert spezifische Modellierungsentscheidungen. Standarddiagramme verbergen oft die Mechanismen zur Lastverteilung. Um Skalierbarkeit zu gewährleisten, müssen Architekten Muster explizit darstellen, die die Arbeit verteilen oder Ressourcen verwalten.
1. Lastverteilung und -verteilung
In Systemen mit hoher Verkehrsdichte kann ein einzelner Prozess nicht alle eingehenden Anfragen bewältigen. Das DFD muss den Verteilungsmechanismus widerspiegeln.
- Router-Muster: Einführung eines Prozessknotens, der den Datenverkehr zu mehreren Diensteknoten leitet.
- Replikation: Zeigen mehrerer identischer Prozesse, die den gleichen Datenstrom für die parallele Verarbeitung erhalten.
- Warteschlangen: Darstellung eines Datenspeichers, der als Puffer vor Beginn der Verarbeitung dient und Spitzen glättet.
Stellen Sie beim Zeichnen eines Routers sicher, dass der Fluss logisch aufgeteilt wird. Wenn das System eine Round-Robin-Strategie verwendet, sollte das Diagramm anzeigen, dass die Entscheidung auf Basis der Last und nicht auf Basis des Dateninhalts getroffen wird. Diese Unterscheidung beeinflusst die Implementierung der Backend-Logik.
2. Asynchrone Verarbeitung
Synchronisierte Abläufe können Engpässe verursachen, wenn ein Schritt auf einen anderen wartet. Asynchrone Muster entkoppeln Prozesse und ermöglichen es dem System, unabhängig zu skalieren.
- Nachrichtenwarteschlangen: Verwenden Sie einen Datenspeicher, um eine Warteschlange darzustellen. Der Produzent schreibt in den Speicher, und der Verbraucher liest später daraus.
- Ereignisströme: Zeigen Sie einen Prozess, der ein Ereignis ausgibt, das mehrere nachgeschaltete Verbraucher auslöst, ohne den Absender zu blockieren.
- Hintergrundaufgaben: Trennen Sie langlaufende Aufgaben von benutzerbezogenen Anfragen, indem Sie sie an einen dedizierten Prozesspool weiterleiten.
Diese Trennung ermöglicht es den benutzerbezogenen Prozessen, leicht zu bleiben, während die schwere Arbeit im Hintergrund erfolgt. Das DFD macht diese Trennung sichtbar und verhindert, dass Entwickler von sofortigen Antwortzeiten ausgehen.
3. Daten-Sharding und -Partitionierung
Mit wachsender Datenmenge werden einzelne Speichereinheiten zu Leistungsbremsern. Sharding-Muster in DFDs helfen dabei, sichtbar zu machen, wie Daten über mehrere Speicher verteilt werden.
- Horizontale Aufteilungen: Zeigen Sie einen Prozess an, der bestimmte Datenuntergruppen basierend auf einer ID oder einem Schlüssel an verschiedene Datenspeicher weiterleitet.
- Lesereplikate: Geben Sie separate Flüsse für das Lesen von Daten aus Replikaten an, während Schreibvorgänge in den primären Speicher gehen.
- Caching-Ebenen: Fügen Sie einen Cache-Datenspeicher zwischen den Prozess und die Hauptdatenbank ein, um die Latenz zu reduzieren.
| Muster | Skalierbarkeitsvorteil | Kompromiss |
|---|---|---|
| Lastverteilung | Erhöht die Durchsatzrate | Erhöhte Komplexität bei der Zustandsverwaltung |
| Asynchrone Warteschlangen | Trennt Abhängigkeiten | Eventuelle Konsistenz |
| Sharding | Erweitert die Speicherkapazität | Komplexe Abfragen über Shards hinweg |
| Caching | Reduziert die Latenz | Risiko von veralteten Daten |
⚠️ Häufige Anti-Muster, die vermieden werden sollten
Selbst mit guten Absichten können DFDs strukturelle Mängel enthalten, die zu Systemausfällen führen. Die frühzeitige Erkennung dieser Anti-Muster verhindert kostspielige Umgestaltungen später.
1. Das Schwarze Loch
Ein Schwarzes Loch tritt auf, wenn ein Prozess Daten empfängt, aber keine Ausgabe erzeugt. Dies geschieht oft, wenn angenommen wird, dass ein Prozess Daten löscht oder stillschweigend verarbeitet.
- Risiko:Datenverlust ohne Fehlerbenachrichtigung.
- Lösung: Stellen Sie sicher, dass jeder Eingang eine entsprechende Ausgangsfluss oder ein klarer Fehlerpfad hat.
- Auswirkung auf Skalierbarkeit:Stille Fehler sind in verteilten Systemen schwer zu debuggen.
2. Das Graue Loch
Ein Graues Loch ist ähnlich einem Schwarzen Loch, hat aber eine teilweise Ausgabe. Der Prozess verbraucht mehr Daten, als er erzeugt, erklärt aber nicht, wohin der Rest verschwunden ist.
- Risiko:Nicht erklärter Datenverbrauch führt zu Speicherlecks oder Transaktionsfehlern.
- Lösung:Modellieren Sie alle Datenpfade explizit, einschließlich Fehlerprotokolle oder Prüfverläufe.
3. Schleifen im Datenfluss
Während einige Rückkopplungsschleifen notwendig sind (z. B. Wiederholungsmechanismen), können unkontrollierte Schleifen unendliche Verarbeitungsschleifen verursachen.
- Risiko:Systemhängen oder Erschöpfung von Ressourcen.
- Lösung:Beschränken Sie die Rekursionstiefe im Diagramm und implementieren Sie Zeitüberschreitungsmechanismen in der Gestaltung.
4. Unendliche externe Entitäten
Das Hinzufügen zu vieler externer Entitäten macht das Diagramm unlesbar und verdeckt die zentrale Logik.
- Risiko:Verlust der Klarheit über die Systemgrenzen.
- Lösung:Gruppieren Sie relevante Entitäten gegebenenfalls in einer einzelnen Entität „System der Aufzeichnung“ oder „Benutzeroberfläche“.
🔄 Best Practices für Wartung und Evolution
Ein DFD ist kein einmaliger Artefakt. Er muss sich entwickeln, während das System wächst. Die Aufrechterhaltung der Genauigkeit des Modells stellt sicher, dass neue Teammitglieder die Architektur verstehen, ohne den Code rückwärts zu analysieren.
- Versionskontrolle:Behandeln Sie Diagramme wie Code. Speichern Sie sie in einer Quellcodeverwaltung, um Änderungen im Laufe der Zeit nachzuverfolgen.
- Namenskonventionen:Verwenden Sie konsistente Benennungen für Prozesse und Datenflüsse. „Benutzer aktualisieren“ sollte immer „Benutzer aktualisieren“ heißen, nicht „Benutzerdetails ändern“.
- Regelmäßige Prüfungen:Planen Sie regelmäßige Überprüfungen, um sicherzustellen, dass das Diagramm der aktuellen Implementierung entspricht.
- Gleichgewicht der Granularität:Machen Sie nicht jeden Prozess zu einem Unterverfahren. Gruppieren Sie verwandte Logik, um eine überschaubare Sicht auf das System zu bewahren.
📝 Abschließende Überlegungen
Eine effektive Systemgestaltung beruht auf klarer Kommunikation. Das Datenflussdiagramm bietet eine gemeinsame Sprache zwischen Architekten, Entwicklern und Stakeholdern. Indem man etablierten Mustern folgt und häufigen Fallen ausweicht, können Teams Systeme aufbauen, die sich reibungslos entwickeln.
Denken Sie daran, dass Diagramme Modelle sind, nicht die Realität selbst. Sie vereinfachen Komplexität, um sie verständlich zu machen. Die Vereinfachung darf jedoch keine kritischen Details bezüglich der Datenintegrität und des Datenflusses entfernen. Wenn ein DFD die Datenbewegung genau widerspiegelt, wird er zu einem leistungsfähigen Werkzeug zur Vorhersage von Engpässen und zur Optimierung der Leistung.
Je verteilter die Systeme werden, desto größer wird der Bedarf an strenger Modellierung. Die hier beschriebenen Muster bilden die Grundlage für diese Strenge. Unabhängig davon, ob Sie eine monolithische Anwendung oder ein Mikroservices-Ökosystem entwerfen, bleiben die Prinzipien des Datenflusses konstant. Konzentrieren Sie sich auf die Bewegung der Informationen, und die Struktur wird sich ergeben.
Beginnen Sie mit dem Kontextdiagramm. Definieren Sie die Grenzen klar. Gehen Sie nur dann in die Prozesse tiefer, wenn es unbedingt notwendig ist. Behalten Sie den Fokus auf Daten, nicht auf der Technologie-Stack. Diese Disziplin stellt sicher, dass die Architektur jahrelang flexibel und skalierbar bleibt.