











Проектирование сложных распределённых систем требует больше, чем просто написание кода; необходимо чёткое визуальное представление, которое могут понять заинтересованные стороны. Диаграммы потоков данных (DFD) служат этим языком, отображая, как информация перемещается между различными узлами, сервисами и единицами хранения. При применении в распределённых средах DFD становятся критически важными инструментами для выявления узких мест, рисков безопасности и проблем согласованности до начала реализации.
В этом руководстве рассматривается методология создания эффективных моделей распределённых систем. Мы изучим основные компоненты, процесс декомпозиции и особые аспекты, которые необходимо учитывать при перемещении данных через границы сети. Следуя установленным практикам моделирования, команды могут обеспечить, что их архитектура поддерживает масштабируемость и надёжность.
🌐 Понимание контекста распределённых систем
Распределённые системы состоят из нескольких автономных компьютеров, которые для пользователей выглядят как единая целостная система. В отличие от монолитных архитектур, такие среды вводят сложность в вопросах коммуникации, управления состоянием и режимов отказов. 🚀 Моделирование этих систем требует смены перспективы — от внутренней логики процессов к внешним путям коммуникации.
- Границы сети:Данные часто пересекают физические или логические сети, что вводит задержки и потенциальные точки отказа.
- Уровень детализации сервисов:Системы разбиваются на более мелкие сервисы, каждый из которых отвечает за конкретные обязанности.
- Безсостоятельность против состоятельности: Некоторые компоненты обрабатывают запросы, не сохраняя историю, в то время как другие управляют постоянными данными.
- Асинхронная коммуникация: Многие взаимодействия в распределённых системах основаны на очередях сообщений, а не на прямых синхронных вызовах.
Без чёткой карты команды рискуют создать «спагетти-архитектуру», в которой потоки данных неясны. Хорошо структурированная DFD уточняет эти взаимодействия, обеспечивая, что каждый элемент данных имеет определённый источник и пункт назначения.
🔍 Роль диаграмм потоков данных в проектировании систем
Диаграмма потоков данных — это графическое представление движения данных через информационную систему. Она не показывает временные интервалы или логику управления, а фокусируется исключительно на том, как данные поступают в систему, преобразуются, перемещаются и покидают её. 🧭
В распределённом контексте DFD помогает визуализировать:
- Откуда поступают данные (внешние сущности).
- Как она обрабатывается (процессы).
- Где она временно или постоянно хранится (хранилища данных).
- Как она перемещается между компонентами (потоки данных).
Использование DFD позволяет архитекторам проверять требования по отношению к предлагаемой архитектуре. Это гарантирует, что никакие данные не создаются или не уничтожаются без веской причины, сохраняя целостность на протяжении всего жизненного цикла.
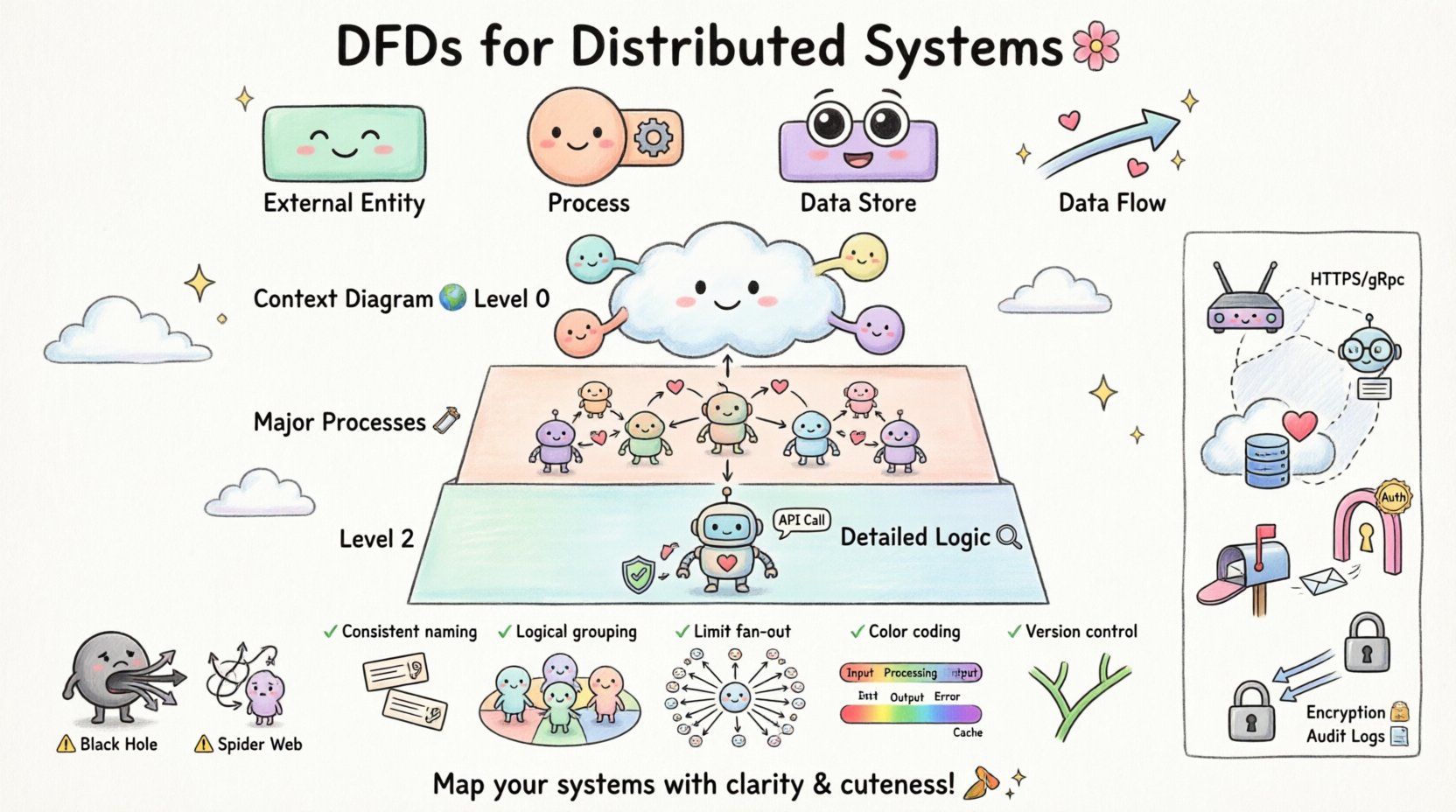
Основные компоненты DFD
Чтобы построить корректную модель, необходимо понимать четыре основных символа, используемых в стандартной нотации. Каждый из них выполняет определённую функцию в графическом представлении.
| Компонент | Функция | Визуальное представление |
|---|---|---|
| Внешняя сущность | Источник или пункт назначения данных за пределами границ системы. | Прямоугольник |
| Процесс | Преобразование данных от входа к выходу. | Круг или закругленный прямоугольник |
| Хранилище данных | Место, где хранятся данные для последующего использования. | Открытый прямоугольник или параллельные линии |
| Поток данных | Передвижение данных между компонентами. | Стрелка |
При моделировании распределённых систем крайне важно помечать каждую стрелку существительным фразой, описывающей содержимое данных, а не глаголом. Например, используйте «Учетные данные пользователя» вместо «Отправка учетных данных».
📉 Уровни декомпозиции потоков данных
Сложные системы нельзя представить в одном виде. Декомпозиция позволяет пройти от общего обзора к детальному анализу. Такой подход предотвращает когнитивную перегрузку читателя.
Уровень 0: Диаграмма контекста
Диаграмма контекста предоставляет самый высокий уровень абстракции. Она показывает всю систему как один процесс и определяет все внешние сущности, взаимодействующие с ней. 🌍
- Область применения:Определяет границы системы.
- Взаимодействия:Показывает все входы и выходы из внешнего мира.
- Чёткость:Помогает заинтересованным сторонам понять цель системы без технических деталей.
Уровень 1: Основные процессы
Уровень 1 расширяет единственный процесс из диаграммы контекста до основных подпроцессов. На этом уровне система разбивается на логические блоки по функциональности. 🛠️
- Декомпозиция:Разделяет систему на 5–9 основных процессов.
- Поток:Показывает, как данные перемещаются между этими основными процессами.
- Хранилища:Вводит хранилища данных, поддерживающие эти процессы.
Уровень 2 и выше: Подробная логика
Дальнейшая декомпозиция происходит на уровне 2, где конкретные подпроцессы разбиваются на более мелкие части. Именно здесь часто начинают проявляться детали реализации, такие как конкретные правила проверки или вызовы API. 🔍
В распределённом моделировании диаграммы уровня 2 особенно полезны для определения границ сервисов. Они помогают определить, какой процесс должен находиться в каком узле сервиса.
⚡ Моделирование распределённых сред
Стандартные диаграммы потоков данных часто предполагают монолитную среду. При адаптации их для распределённых систем необходимо применять специфические обозначения и учитывать особенности, отражающие реальность сети. 🌐
Вот сравнение элементов стандартного и распределённого моделирования:
| Элемент | Стандартное моделирование | Распределённое моделирование |
|---|---|---|
| Поток данных | Прямой логический поток. | Передача по сети, задержка, протокол. |
| Процесс | Одиночный вычислительный блок. | Микросервис, контейнер или функция без сервера. |
| Хранилище данных | Локальная база данных. | Облачное хранилище, распределённый кэш или фрагментированная база данных. |
| Граница | Граница системы. | Граница сети, зона доверия или шлюз API. |
При рисовании потоков данных между процессами в разных узлах полезно аннотировать поток механизмом передачи (например, HTTPS, gRPC, очередь сообщений). Это добавляет контекст по требованиям к производительности и безопасности.
🛡️ Обработка параллелизма и состояния
Распределённые системы часто обрабатывают одновременные запросы. Статическая диаграмма потоков данных может не показывать время явно, но должна подразумевать, как управляет состоянием в ходе этих взаимодействий.
- Процессы без состояния: Если процесс не хранит состояние, диаграмма потоков данных должна показывать, как данные проходят через него и выходят, не возвращаясь в хранилище для этой конкретной транзакции.
- Процессы с состоянием: Если процесс сохраняет состояние, должен быть чёткий поток данных к хранилищу данных, которое сохраняет эту информацию.
- Согласованность: Потоки данных, представляющие обновления, должны указывать, как обеспечивается согласованность между узлами.
Например, при моделировании корзины покупок диаграмма потоков данных должна показывать, как «данные корзины» проходят от сущности Пользователь к сервису Корзины, а затем к хранилищу базы данных. Если сервис корзины распределён, поток должен указывать, какой узел хранит авторитетную копию данных.
🚫 Распространённые ошибки при распределённом моделировании
Даже опытные архитекторы могут допускать ошибки при визуализации распределенных потоков данных. Осознание этих распространенных ошибок помогает улучшить качество модели. 🚧
| Ловушка | Влияние | Исправление |
|---|---|---|
| Процесс-черная дыра | Данные поступают в процесс, но никогда из него не выходят. | Убедитесь, что каждый вход имеет соответствующий выход или хранилище. |
| Процесс-серая дыра | Выходы существуют, но ни один вход не объясняет их. | Проверьте все источники данных для каждого выходного потока. |
| Паутина | Слишком много пересекающихся линий, вызывающих путаницу. | Используйте подпроцессы для группировки связанных потоков. |
| Пренебрежение сетью | Пренебрежение задержками или точками отказа. | Добавьте примечания к потокам с указанием протокола и надежности. |
Избегайте прямых соединений между хранилищами данных без промежуточного процесса. Хранилища данных должны взаимодействовать только через процессы, которые проверяют и преобразуют данные. Это предотвращает несанкционированный прямой доступ и обеспечивает применение бизнес-логики.
📝 Лучшие практики для ясности
Создание диаграммы, которая одновременно точна и легко читаема, требует соблюдения определенных принципов проектирования. 🎨
- Согласованное наименование: Используйте одну и ту же терминологию для одних и тех же данных во всех диаграммах. Если в уровне 0 используется «User ID», не называйте его «Customer Key» на уровне 1.
- Логическая группировка: Визуально группируйте связанные процессы. Это помогает определить границы сервисов.
- Ограничьте количество отходящих потоков: Избегайте ситуации, когда один процесс соединен более чем с десятью потоками данных. В таком случае разбейте процесс.
- Цветовая кодировка: Используйте цвета для различения внутренних процессов, внешних сущностей и хранилищ данных. Это облегчает быстрый просмотр.
- Контроль версий: Рассматривайте диаграммы как код. Храните их в системе контроля версий, чтобы отслеживать изменения с течением времени.
При моделировании распределенных систем рассмотрите возможность использования полос (swimlanes) для представления различных зон доверия или сетевых сегментов. Это сразу делает очевидным, какие компоненты ориентированы на публичный доступ, а какие — внутренние.
🔒 Интеграция аспектов безопасности
Безопасность — это не после мысли; она должна моделироваться одновременно с функциональностью. Диаграммы потоков данных предоставляют уникальную возможность выявить риски безопасности на ранней стадии проектирования.
- Точки аутентификации:Отметьте, где проверяются учетные данные пользователя. Обычно это происходит на границе между внешним сущностью и первым процессом.
- Шифрование данных:Укажите, где потоки чувствительных данных шифруются. Используйте метки, такие как «Зашифрованный канал» на стрелке.
- Контроль доступа:Покажите, какие процессы имеют разрешение на доступ к конкретным хранилищам данных.
- Ведение журнала:Включите потоки, отправляющие журналы аудита в отдельное хранилище журнала. Это обеспечивает возможность отслеживания.
Явно моделируя эти потоки безопасности, команды могут убедиться, что шифрование и аутентификация не будут упущены при реализации. Это вынуждает обсуждать вопросы конфиденциальности данных и требований соответствия.
🔄 Обслуживание и эволюция
Системы эволюционируют. Требования меняются, добавляются новые службы. Диаграмма потоков данных — это живой документ, который необходимо поддерживать, чтобы оставаться полезным. 🔄
- Регулярные обзоры:Планируйте регулярные обзоры диаграмм потоков данных совместно с командой разработки, чтобы убедиться, что они соответствуют текущей базе кода.
- Управление изменениями: Когда добавляется новая функция, немедленно обновите диаграмму. Не ждите следующего спринта документации.
- Отслеживание зависимостей: Используйте диаграмму для отслеживания зависимостей. Если хранилище данных удаляется, диаграмма покажет, какие процессы будут нарушены.
Документация, не отражающая реальность, создает технический долг. Поддержание актуальности диаграмм потоков данных сокращает время настройки новых инженеров и предотвращает отклонение архитектуры.
🛠️ Стратегия реализации
Как на самом деле начать моделирование сложной системы? Следуйте структурированному подходу, чтобы обеспечить полноту.
- Определите сущности: Перечислите всех пользователей, внешних систем и устройств, взаимодействующих с системой.
- Определите границы:Четко нарисуйте линию границы системы. Все, что внутри, — это система; все, что снаружи, — внешнее.
- Создайте карту высокого уровня потоков:Сначала нарисуйте диаграмму контекста. Убедитесь, что учтены все входы и выходы.
- Разбейте процессы:Разбейте основной процесс на подпроцессы. Обозначьте их глаголами.
- Добавить хранилища данных: Определите, где данные должны быть сохранены. Подключите их к соответствующим процессам.
- Проверить: Проверьте наличие черных и серых дыр. Убедитесь, что каждый поток имеет источник и пункт назначения.
- Уточнить: Добавьте сведения о протоколах, шифровании и границах сети для распределённых контекстов.
Этот итеративный процесс гарантирует, что модель будет надежной до написания кода. Он экономит время, позволяя выявлять логические ошибки на ранних этапах.
🚀 Заключение
Диаграммы потоков данных — это фундаментальный инструмент для проектирования распределённых систем. Они обеспечивают необходимую ясность для понимания того, как данные перемещаются по сложным сетям. Следуя лучшим практикам, избегая распространённых ошибок и поддерживая диаграммы в актуальном состоянии, команды могут создавать масштабируемые, защищённые и надёжные системы. 🌟
Вложения в моделирование окупаются на этапах разработки и сопровождения. Чёткие диаграммы способствуют лучшему взаимодействию между разработчиками, заинтересованными сторонами и командами эксплуатации. Они служат единственным источником истины для архитектуры системы.
Начните создавать карты своих распределённых систем уже сегодня. Сосредоточьтесь на чёткости, согласованности и точности. Ваш будущий я скажет вам спасибо, когда архитектуре потребуется масштабирование или при наboardingе новых членов команды. 🏁