











在系统架构与安全工程的领域中,可视化数据流动不仅是一种设计练习;更是一种基本的安全实践。数据流图(DFD)是系统中信息流动的路线图。当正确用于风险分析时,这张图便成为在生产环境出现漏洞之前识别脆弱性的关键工具。本指南详细介绍了将风险识别与缓解策略直接整合到DFD创建过程中的方法。
安全不是附加功能;而是设计的固有属性。通过分析数据在外部实体、处理过程和数据存储之间的流动方式,架构师可以精准定位信任边界被跨越、敏感信息暴露以及控制措施缺失的位置。接下来的章节将探讨这种方法的机制,从基础概念逐步过渡到实际应用。
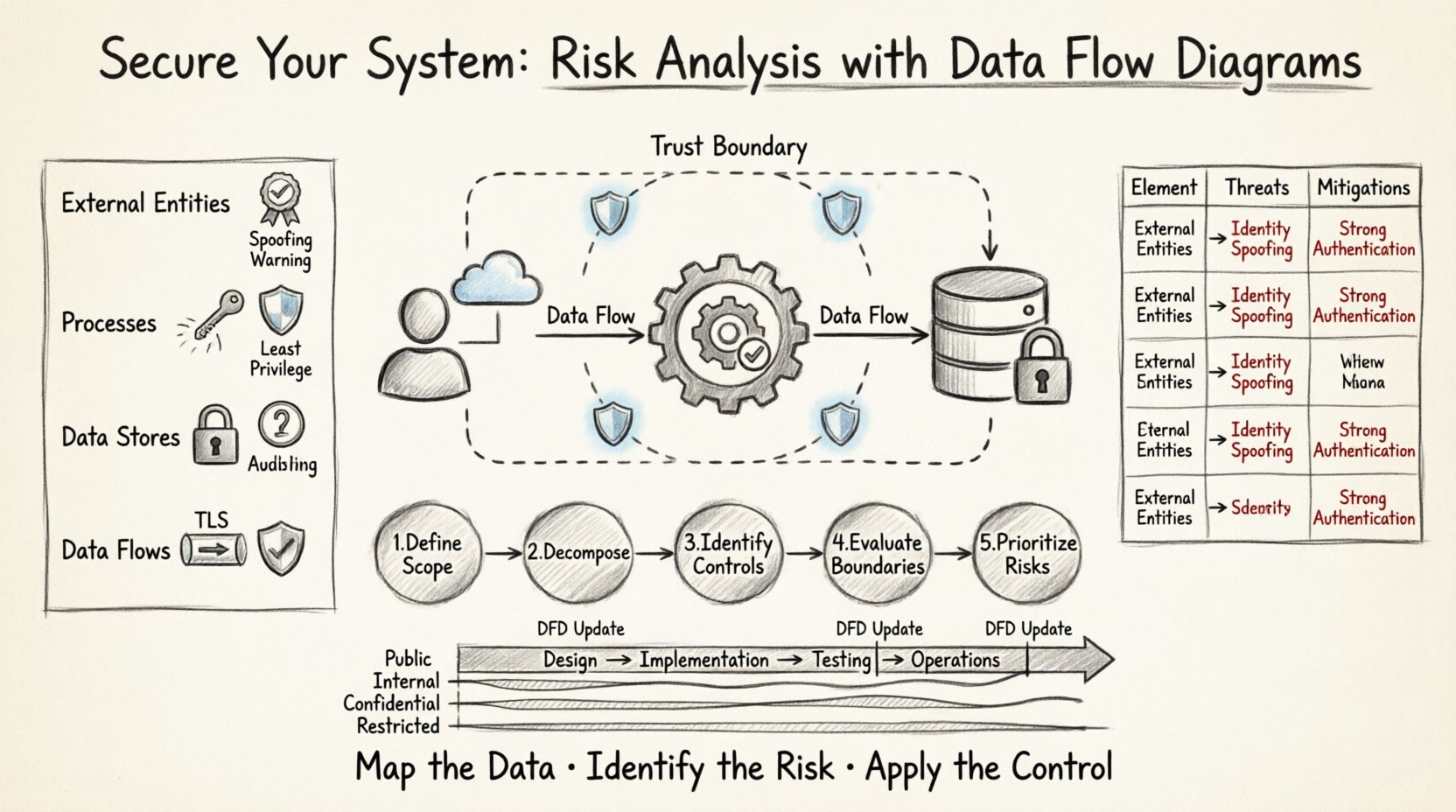
🧩 理解数据流图的核心要素
在分析风险之前,必须先理解所分析的组件。数据流图(DFD)由四个主要元素构成。每个元素都具有特定的安全影响,必须在审查过程中加以评估。
- 外部实体: 这些代表系统边界之外的数据来源或目的地。例如用户、其他系统或第三方服务。 安全影响: 实体通常是伪造攻击或未经授权访问尝试的来源。在与内部流程交互之前,每个实体都必须经过身份验证和授权。
- 处理过程: 这些是对数据执行功能或转换的处理单元。它们将输入数据转换为输出数据。 安全影响: 处理过程是逻辑错误发生的地方。如果一个过程未能验证输入,可能导致注入攻击或逻辑绕过。确保每个处理过程的执行上下文都遵循最小权限原则至关重要。
- 数据存储: 这些代表数据静止存放的位置。可以是数据库、文件或内存缓冲区。 安全影响: 数据存储是数据窃取的主要目标。此处必须实施访问控制、静态加密和完整性检查。
- 数据流: 这些是数据在其他三个元素之间流动的路径。 安全影响: 数据流代表网络或进程间通信的通道。传输中的数据必须加密。监控未经授权的数据流对于检测攻击者横向移动至关重要。
🔍 数据流图与威胁建模的交汇点
将风险分析整合到DFD中需要采用结构化的方法。这通常被称为使用数据流图进行威胁建模。其目标是识别与每个元素和数据流相关的潜在威胁,然后确定适当的缓解措施。
在进行此类分析时,关注点从“系统是如何工作的?”转变为“系统可能如何被攻击?”。这种视角的转变使团队能够主动设计控制措施,而非被动地修补漏洞。
DFD风险分析的关键目标
- 资产识别: 确定哪些数据元素是敏感的。并非所有数据都需要同等程度的保护。
- 信任边界定义: 明确标出系统边界结束和外部环境开始的位置。信任级别在这些边界之间会发生变化。
- 威胁枚举: 列出适用于图表元素的具体威胁。
- 控制映射: 将安全控制分配给特定的图表元素,以减轻已识别的威胁。
📉 按DFD层级分析风险
数据流图通常按层级创建,从高层次的上下文逐步深入到详细的过程逻辑。每一层级提供不同粒度的风险洞察。
上下文图(第0层)
这是最高层级的视图。它将系统显示为一个与外部实体交互的单一过程。
- 风险重点: 网络边界安全和高层级访问控制。
- 分析: 识别所有外部连接。是否存在直接的互联网连接?是否有遗留系统与新设计进行交互?此层级的高层风险包括主要通信通道上的中间人攻击。
第1层DFD
主过程被分解为子过程。数据存储和数据流变得可见。
- 风险重点: 内部数据处理和过程隔离。
- 分析: 寻找绕过安全检查的数据流。例如,数据是否从不可信实体直接流向敏感数据存储,而未经过验证流程?此层级常揭示认证流程中的逻辑漏洞。
第2层DFD(及更高层级)
子过程进一步细化。此层级常用于特定模块的分析。
- 风险重点: 数据验证、加密实现和错误处理。
- 分析: 检查特定的算法或数据转换。加密操作是否明确显示?错误消息是否以泄露信息的方式被记录?此层级对于代码级别的安全审查至关重要。
📋 风险矩阵:将元素映射到威胁
下表总结了与特定DFD元素相关的常见风险。该矩阵在设计评审阶段可作为检查清单使用。
| DFD元素 | 常见威胁 | 缓解策略 |
|---|---|---|
| 外部实体 |
|
|
| 流程 |
|
|
| 数据存储 |
|
|
| 数据流 |
|
|
🛠️ 风险分析的逐步流程
实施此分析需要有条不紊的工作流程。以下步骤概述了使用数据流图(DFDs)进行彻底风险审查的程序。
步骤1:定义范围和边界
首先绘制上下文图。明确界定系统内部和外部的内容。此边界即为信任边界。任何跨越此边界的数据显示都需要仔细审查。记录每个外部实体所分配的信任级别。该实体是完全可信、部分可信还是不可信?
步骤2:分解系统
创建第1级和第2级图表。在分解主流程时,确保每个数据流都标注了传输的数据类型。例如,应将一个数据流标记为“信用卡号码”,而不是仅标记为“支付数据”。具体性有助于实现更精确的风险分类。
步骤3:识别安全控制
根据风险矩阵审查每个图表元素。针对每个组件提出以下问题:
- 此组件是否处理敏感数据?
- 是否已部署认证机制?
- 数据在传输过程中是否已加密?
- 是否生成日志以供审计?
步骤4:评估信任边界
在图表中标记每一个信任边界。信任边界是信任级别发生变化的位置。例如,公共Web服务器与内部数据库之间存在一个边界。跨越此边界是风险最高的点。确保每个跨越点都有特定的安全控制措施,例如防火墙规则、API网关或加密隧道。
步骤5:记录并优先处理风险
列出所有识别出的风险。使用严重性评级系统(例如:低、中、高、严重)。根据两个因素对风险进行优先排序:被利用的可能性以及风险实际发生时的业务影响。高影响风险应在部署前得到解决。
🚧 DFD安全分析中的常见陷阱
即使经验丰富的架构师也可能忽略关键细节。了解常见错误有助于确保具备稳健的安全态势。
- 幽灵流:确保每个数据流都有明确的来源和目的地。那些起点或终点不明的数据流通常表明存在缺失的逻辑或孤立的数据处理流程。这些漏洞可能被攻击者利用。
- 忽视静态数据:仅关注传输中的数据。许多安全事件的发生是因为存储在数据库中的数据未被加密,或可通过权限过宽的查询访问。
- 忽视认证:认为只要存在数据流就一定是安全的。数据流并不自动意味着安全。必须显式地将认证和授权步骤建模为流程或控制措施。
- 缺乏版本控制:随着系统的变化,DFD也会随之演变。如果图表与当前实现不一致,风险分析将无效。应与代码版本同步维护图表的版本控制。
- 通用标签:使用“用户数据”等模糊标签而未明确数据类型。具体的数据类型会触发特定的监管和安全要求(例如:PII、PHI、PCI-DSS)。
🔄 融入开发生命周期
为了使DFD分析有效,它不能仅作为一次性事件。必须将其融入软件开发生命周期(SDLC)中。
设计阶段
在初始设计阶段,创建上下文图和第1级图表,并进行高层次的风险评估。这可以确保基本的安全缺陷不会被固化在架构中。
实现阶段
在开发人员构建功能时,应更新第2级图表。这能确保安全模型保持最新。开发人员可利用图表验证其代码是否实现了针对所编写数据流的必要控制措施。
测试阶段
安全测试人员可以使用数据流图(DFD)来规划渗透测试。他们可以专注于分析中识别出的高风险数据流和信任边界。这使得测试更加高效且具有针对性。
运维阶段
在运维过程中保持图表的更新。如果集成了新的第三方服务,应及时更新图表。审查风险分析,确保新集成不会引入新的攻击面。
📈 衡量分析有效性的方法
如何判断DFD风险分析是否有效?请关注以下体现成熟安全态势的指标。
- 漏洞数量减少:代码审查和渗透测试中的安全发现数量减少。
- 更快的修复: 发现问题时,由于数据流已被记录,更容易定位。
- 合规性对齐: 图表通过展示敏感数据的处理和存储位置,直接对应合规性要求(例如GDPR、HIPAA)。
- 团队意识: 开发人员和利益相关者理解其设计选择的安全影响,因为图表直观展示了风险。
🛑 处理例外情况和遗留系统
并非所有系统都是新建的。许多组织必须分析那些文档缺失或不完整的遗留系统。
逆向工程数据流图
如果不存在图表,必须从代码或配置文件中创建一个。这一过程称为逆向工程,它使你能够可视化实际的数据流,而非预期的数据流。实际数据流与预期设计之间的差异,往往是风险隐藏的地方。
管理技术债务
遗留系统可能缺乏现代安全功能。在分析这些系统时,应重点关注补偿控制措施。如果无法在代码层面实现加密,是否可以在网络层面实现?如果认证较弱,是否可以通过API网关在遗留应用前增加一层安全防护?
🔗 数据分类的作用
风险识别与数据分类密不可分。你无法保护自己不了解的内容。数据流必须标注相应的分类级别。
- 公开: 可以公开共享的信息。若泄露,风险较低。
- 内部: 仅限内部使用的信息。若泄露,风险中等。
- 机密: 敏感的业务或个人数据。若泄露,风险较高。
- 限制: 极其敏感的数据,需要严格的访问控制。若泄露,风险极高。
在分析数据流图(DFD)时,用不同颜色突出显示包含机密或受限数据的流程。这一视觉提示能立即引导安全团队关注最关键的路径。
🧭 方法论总结
利用数据流图进行风险识别,将安全从被动的检查清单转变为积极的设计原则。通过可视化数据的流动,团队能够发现隐藏在架构中的无形威胁。这一过程需要纪律性、定期更新以及对系统组件的清晰理解。正确执行后,它能为防范已知和新兴威胁提供明确的路线图。
这种方法的价值在于清晰性。它迫使架构师面对数据如何流动以及何处存在脆弱性的现实。它消除了安全讨论中的模糊性。随着系统复杂性的增加,这种结构化分析的需求变得更加关键。保持图表的准确性并严格应用风险分析,可确保安全始终与软件整个生命周期中的业务功能保持一致。
从图表开始。映射数据。识别风险。实施控制。这一循环能够构建出能够抵御现代威胁环境压力的弹性系统。