











在系统设计和需求工程的领域中,清晰性至关重要。当利益相关者难以可视化信息在系统中的流动方式时,项目往往陷入停滞。这时,数据流图(DFD)便成为业务分析师不可或缺的工具。与静态图表或复杂代码不同,DFD能够描绘数据从进入系统到离开系统的全过程,突出显示数据的转换和存储点。本指南将探讨DFD的运作机制、其结构组成,以及其在成功业务分析中的关键作用。
无论你是绘制遗留系统还是设计新的数字平台,理解信息的流动都是有效建模的核心。我们将介绍核心符号、图表的层级结构,以及确保准确性的具体规则。没有夸大其词,只有构建稳健系统文档所必需的结构完整性。
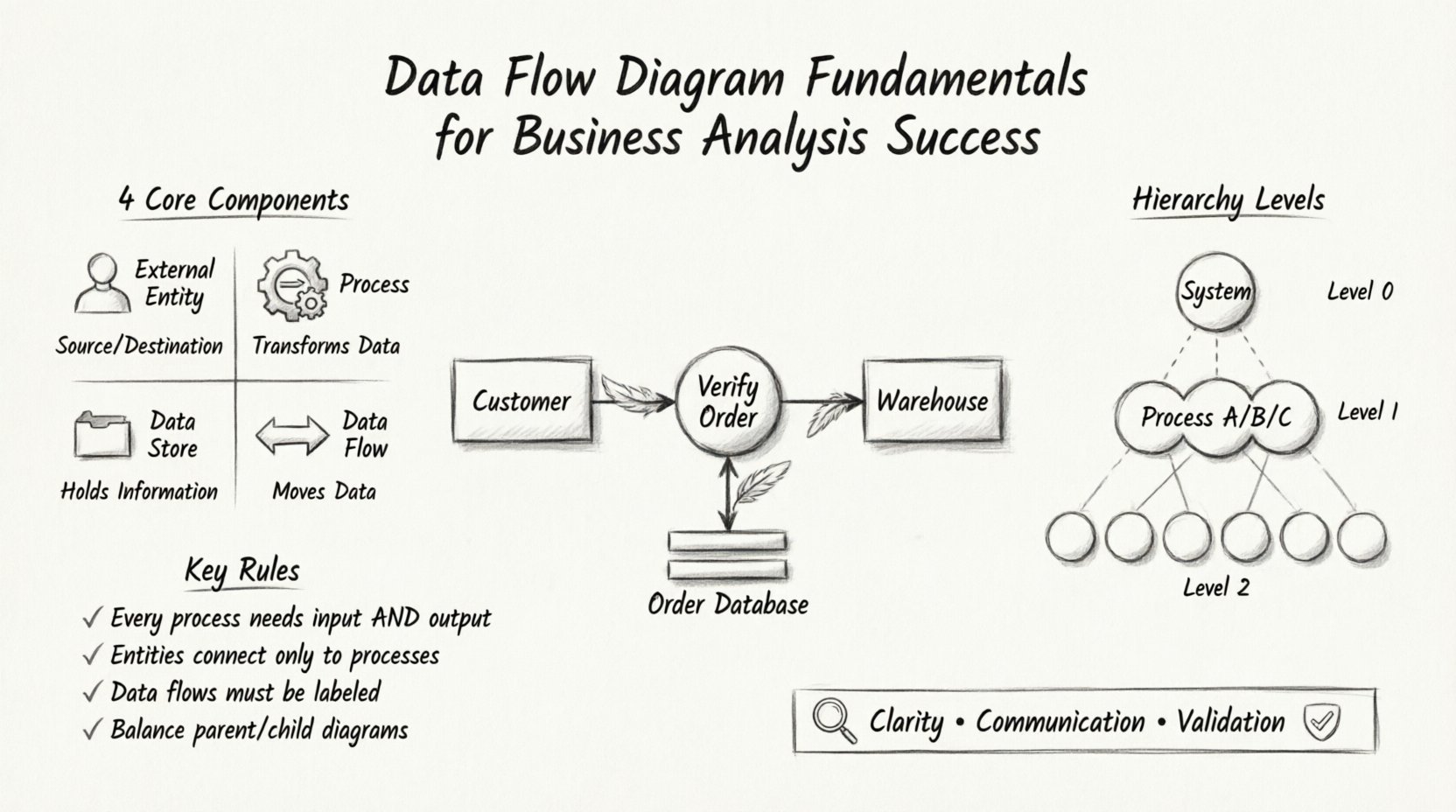
什么是数据流图?🤔
数据流图是一种图形化表示,用于展示数据在信息系统中的流动过程。它通过显示系统的输入和输出来建模数据如何被处理。与侧重于流程逻辑和决策顺序的流程图不同,数据流图关注的是数据本身。
主要特征包括:
- 关注数据: 它追踪数据对象,而非控制逻辑。
- 以过程为导向: 它展示了数据在系统中流动时如何发生变化。
- 抽象性: 它隐藏了内部实现细节,关注的是“做什么”而非“怎么做”。
- 独立性: 它描述系统需求,而不将其与特定技术绑定。
对于业务分析师而言,DFD充当了沟通的桥梁。它将技术需求转化为非技术人员可以审查和验证的可视化格式。这减少了歧义,确保所有人就系统如何处理信息达成一致。
DFD的核心组件 🧩
每个有效的数据流图都由四个基本要素构成。理解这些要素是绘制准确图表的前提。无论使用何种方法或工具,这些符号始终保持一致。
1. 外部实体(源与目标) 👤
外部实体代表与被建模系统交互的人、组织或其他系统。它们是数据流的起点(源)或终点(目标)。它们存在于系统边界之外。
- 示例: 客户、银行、政府机构或第三方API。
- 符号表示: 通常用矩形或代表人物的图标表示。
- 规则: 每个数据流必须连接到一个处理过程;不能直接连接到另一个实体。
2. 处理过程(转换) ⚙️
处理过程将输入数据转换为输出数据。它描述了对数据执行的功能、活动或计算。这是系统内部“工作”发生的地方。
- 示例: “计算总额”,“验证用户”,“生成报告”。
- 符号表示: 通常是一个圆或圆角矩形。
- 规则: 每个过程必须至少有一个输入和一个输出。一个有输入但没有输出的过程是不可能的。
3. 数据存储(仓库) 📁
数据存储表示信息被保存以供后续使用的位置。这可以是一个数据库、一个文件、一份纸质文件或一个实体仓库。它不处理数据;它只是保存数据。
- 示例:客户数据库、库存文件、订单日志。
- 符号表示:通常是一个开口的矩形或平行线。
- 规则:数据流必须连接过程与数据存储。数据存储不能直接连接到外部实体。
4. 数据流(流动) 🔄
数据流表示实体、过程和存储之间数据的流动。它们代表正在传输的实际数据包。
- 示例: “发票”,“付款详情”,“搜索查询”。
- 符号表示: 一个指向数据流动方向的箭头。
- 规则: 箭头必须标注。未标注的流是没有意义的。
下表总结了这些组件之间的关系,以方便快速查阅。
| 组件 | 功能 | 连接规则 |
|---|---|---|
| 外部实体 | 源或目标 | 仅连接到一个过程 |
| 过程 | 转换数据 | 连接到实体、存储和其他过程 |
| 数据存储 | 存储数据 | 仅连接到一个过程 |
| 数据流 | 传输数据 | 必须标注;不能直接连接实体到实体 |
DFD分解的层级 📉
单个图表很少能完全体现系统的全部复杂性。为了管理细节,DFD会被分解为不同的层级。这种层次结构使分析人员能够放大和缩小系统视图。
上下文图(第0层) 🌍
上下文图是抽象程度最高的图表。它将系统表示为一个单一的过程,并标识出与之交互的外部实体。它定义了系统的边界。
- 范围: 一个代表整个系统的中心过程。
- 细节: 仅显示主要的数据输入和输出。
- 用途: 用于最初与利益相关者就系统范围达成一致。
第1层图 🏗️
第1层图将上下文图中的单一过程扩展为子过程。它将系统的主功能进行分解。
- 范围: 系统的内部过程可见。
- 细节: 显示数据在内部功能之间如何流动。
- 用途: 用于详细的功能需求。
第2层及更深层 🧱
如果第1层中的某个过程仍然过于复杂,则会进行进一步分解。第2层图将特定的第1层过程分解为更细的步骤。
- 范围: 特定功能内的详细逻辑。
- 细节: 具体的数据转换和本地存储。
- 用途: 用于实施特定模块的开发团队。
平衡原则 ⚖️
DFD建模中最关键的规则之一是平衡。平衡确保父图与其子图之间的一致性。当一个过程被展开为更低层级的图表时,其输入和输出必须保持不变。
如果一个0层过程接收“订单数据”并发送“收据数据”,那么表示该过程的1层图也必须接收“订单数据”作为输入,并发送“收据数据”作为输出。内部复杂性发生变化,但与外部世界的接口保持不变。这确保了在分解过程中不会创建或销毁任何数据。
逐步创建过程 🛠️
创建一个稳健的DFD需要采用结构化的方法。急于求成会导致错误和混乱。遵循以下步骤,以构建一个可靠的模型。
1. 确定系统边界
定义系统内部和外部的内容。这决定了哪些实体是外部的,哪些过程是内部的。边界之外的所有内容都是外部实体。
2. 标绘外部实体
列出所有与解决方案交互的人、部门或系统。将它们放置在图表的外围。除非内部用户作为外部数据源,否则不要包含他们。
3. 定义主要过程
识别处理数据所需的主要功能。使用动作动词命名(例如,“处理付款”而非“付款”)。确保流程具有逻辑顺序。
4. 绘制数据流
将实体连接到过程,将过程连接到数据存储。确保每条数据流都有标签,描述其传输的数据。尽可能避免线条交叉,以保持可读性。
5. 审查与验证
对照平衡规则进行检查。确认每个过程都有输入和输出。确保没有数据存储在没有中间过程的情况下被访问。将草图提交给利益相关者以获取反馈。
清晰命名规范 🏷️
标签杂乱的图表会违背其初衷。清晰的命名规范可以降低读者的认知负担。
过程名称
- 使用动词加名词的结构(例如,“更新客户档案”)。
- 名称应简短但具有描述性。
- 避免使用“过程1”或“做某事”之类的通用术语。
数据流名称
- 命名数据本身,而非动作(例如,“发票详情”而非“发送发票”)。
- 在整个图表中一致使用单数或复数形式。
- 确保名称与数据字典或需求文档一致。
数据存储名称
- 使用名词短语来表示所存储的内容(例如,“订单文件”或“客户列表”)。
- 不要使用动词短语。
常见陷阱及避免方法 ⚠️
即使是经验丰富的分析师也会犯错。及早识别常见错误可以避免后期大量返工。
1. 悬空的数据流
一种从无处开始或结束的数据流。每个箭头都必须连接两个有效的组件。
- 修复:追踪每一根线条。如果线条在空白处结束,就将其连接到一个处理过程或实体。
2. 黑洞
一个有输入但无输出的处理过程。这意味着数据被消耗却未被使用或存储。
- 修复:确保每个处理过程都生成某种形式的输出,无论输出到存储、实体还是另一个处理过程。
3. 奇迹过程
一个有输出但无输入的处理过程。这意味着数据凭空出现。
- 修复:确定数据的来源。将其连接到一个实体或数据存储。
4. 实体到实体的直接数据流
数据不能在不经过系统(处理过程)的情况下,从一个外部实体直接流向另一个外部实体。
- 修复:将所有外部数据流通过至少一个内部处理过程。
5. 过早地加入过多细节
在未建立上下文或一级视图的情况下,直接从二级图开始。
- 修复:从宏观入手。首先定义系统边界。只有在高层视图获得批准后,才进行分解。
将DFD融入现代业务分析实践 🔄
数据流图并非孤立的产物。它们融入更广泛的业务分析流程中,尤其是在敏捷和迭代环境中。
敏捷兼容性
在敏捷环境中,通常不鼓励过度文档化。然而,像DFD这样的可视化模型对于复杂逻辑仍然具有价值。它们可以作为“足够”的文档来指导开发,而不会成为瓶颈。使用它们来澄清涉及复杂数据转换的用户故事。
需求可追溯性
DFD中的每个处理过程都应对应一个功能需求。这会创建一个可追溯性矩阵,使你能够验证每个需求是否在模型中得到体现。如果存在没有对应处理过程的需求,系统设计就是不完整的。
利益相关者沟通
技术术语常常让业务用户感到疏远。DFD提供了一种通用语言。业务用户可以指向一个数据存储并问:“我们把这段历史存放在哪里?”分析人员随后可以验证图中是否存在该存储。这有助于需求的协作式优化。
准确性验证技术 📏
一旦绘制完图表,就必须进行测试。验证数据流图(DFD)可以确保它准确地反映了现实世界中的操作。
走查
与领域专家一起进行走查。在图表中追踪一个具体的交易流程。例如,追踪“采购订单”从创建到归档的整个生命周期。如果路径中断或逻辑不合理,图表就需要修改。
数据字典交叉引用
将数据流上的标签与你的数据字典进行对比。确保字典中定义的数据结构与图表中传输的数据一致。如果字典将“客户ID”定义为字符串,但数据流暗示其为数字,则存在不一致。
一致性检查
检查多个图表之间的一致性。如果某个过程出现在一级图表中,那么进入和离开该过程的数据流必须与二级分解图中的数据流一致。此处的不一致表明逻辑上存在漏洞。
数据存储在分析中的作用 🗃️
数据存储常常被忽视,但它们代表了系统的状态。理解它们对于数据治理和数据完整性至关重要。
读取与写入操作
并非所有对数据存储的连接都相同。有些过程仅读取数据(例如,“显示历史记录”),而其他过程则写入或更新数据(例如,“保存订单”)。尽管传统数据流图使用同一条线表示两者,但理解这一区别有助于后续的数据库设计。只读存储不需要特定用户的写入权限。
临时存储与永久存储
区分临时缓冲区和永久归档。临时存储可能在批量计算期间保存数据,而永久存储则为合规性目的保留数据。这种区分会影响安全要求和保留策略。
关于DFD实用性的结论 🚀
数据流图仍然是业务分析中历久弥新的工具。它们剔除了实现细节的干扰,揭示了信息流动的核心。通过严格遵守组件、平衡和命名方面的规则,分析师可以创建出作为系统开发可靠蓝图的模型。
业务分析的成功取决于清晰性。一个构建良好的数据流图能提供这种清晰性。它能统一利益相关者,指导开发人员,并确保最终系统按预期运行。正确使用时,数据流图不仅仅是绘图,更是业务需求与技术解决方案之间的契约。
关注数据。尊重边界。验证流程。这种严谨的方法将产生经得起时间与变化考验的图表。