











设计复杂的分布式系统不仅需要编写代码,更需要一种清晰的视觉语言,让利益相关者能够理解。🏗️ 数据流图(DFD)正是这种语言,用于描绘信息在不同节点、服务和存储单元之间的流动方式。在分布式环境中应用数据流图,能够成为关键工具,在实施开始前识别瓶颈、安全风险和一致性挑战。
本指南探讨了构建有效分布式系统模型的方法论。我们将分析核心组件、分解过程,以及当数据跨越网络边界时所需考虑的特定问题。通过遵循既定的建模实践,团队可以确保其架构具备可扩展性和可靠性。
🌐 理解分布式系统的上下文
分布式系统由多个自治计算机组成,对用户而言表现为一个单一的、连贯的系统。与单体架构不同,这些环境在通信、状态管理和故障模式方面引入了复杂性。🚀 建模这些系统需要从内部过程逻辑的视角,转向外部通信路径的视角。
- 网络边界:数据经常跨越物理或逻辑网络,引入延迟和潜在的故障点。
- 服务粒度:系统被拆分为更小的服务,每个服务负责特定职责。
- 无状态与有状态:某些组件在不保留历史记录的情况下处理请求,而其他组件则管理持久化数据。
- 异步通信:许多分布式交互依赖消息队列,而非直接的同步调用。
如果没有清晰的蓝图,团队可能会创建一种“意大利面式架构”,其中数据流动不清晰。一个结构良好的数据流图能够明确这些交互,确保每个数据点都有明确的来源和目的地。
🔍 数据流图在系统设计中的作用
数据流图是信息系统中数据流动的图形化表示。它不展示时间或控制逻辑,而是严格聚焦于数据如何进入、转换、移动和退出系统。🧭
在分布式环境中,数据流图有助于可视化:
- 数据的来源(外部实体)。
- 它如何被处理(处理过程)。
- 它被临时或永久存储的位置(数据存储)。
- 它在组件之间如何传输(数据流)。
使用数据流图使架构师能够将需求与所提出的架构进行验证。它确保数据不会在没有正当理由的情况下被创建或销毁,从而在整个生命周期中保持完整性。
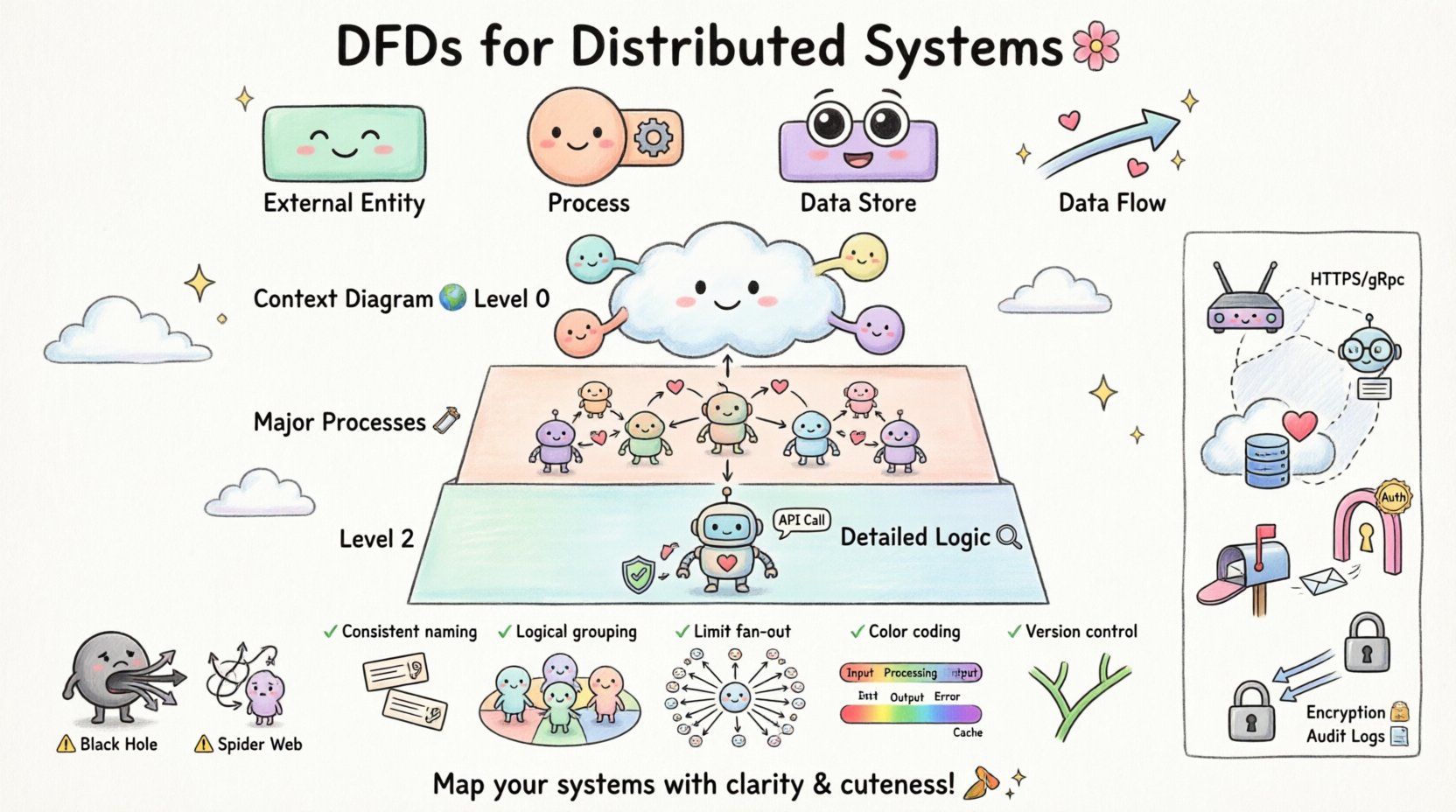
数据流图的核心组件
要构建一个有效的模型,必须理解标准符号中使用的四种主要符号。每个符号在图示表示中都具有独特的作用。
| 组件 | 功能 | 视觉表示 |
|---|---|---|
| 外部实体 | 系统边界之外的数据源或目标。 | 矩形 |
| 处理 | 将输入数据转换为输出数据。 | 圆或圆角矩形 |
| 数据存储 | 数据被保存以供后续使用的地点。 | 开口矩形或平行线 |
| 数据流 | 数据在组件之间的移动。 | 箭头 |
在建模分布式系统时,必须用描述数据内容的名词短语来标记每个箭头,而不是动词。例如,使用“用户凭据”而不是“发送凭据”。
📉 数据流图的分解层级
复杂系统无法在单一视图中表示。分解使您能够从高层次概览深入到细致的细节。这种方法可防止读者产生认知过载。
第0层:上下文图
上下文图提供了最高级别的抽象。它将整个系统表示为一个单一的处理过程,并识别出与之交互的所有外部实体。🌍
- 范围: 定义系统的边界。
- 交互: 显示来自外部世界的所有输入和输出。
- 清晰度: 帮助利益相关者在无需技术细节的情况下理解系统的目的。
第1层:主要过程
第1层将上下文图中的单一过程扩展为多个主要子过程。该层级根据功能将系统划分为逻辑模块。🛠️
- 分解: 将系统划分为5到9个主要过程。
- 流: 显示数据在这些主要过程之间的流动方式。
- 存储: 引入支持这些过程的数据存储。
第2层及更高层:详细逻辑
第2层进行进一步的分解,将特定的子过程细化。这通常是实现细节开始显现的地方,例如特定的验证规则或API调用。🔍
在分布式建模中,二级图特别有助于定义服务边界。它们有助于确定哪个进程应位于哪个服务节点中。
⚡ 建模分布式环境
标准的DFD通常假设为单体环境。在将其适应于分布式系统时,必须应用特定的符号和考虑因素,以反映网络现实。🌐
以下是标准建模与分布式建模元素的对比:
| 元素 | 标准建模 | 分布式建模 |
|---|---|---|
| 数据流 | 直接的逻辑流。 | 网络传输、延迟、协议。 |
| 处理过程 | 单一计算单元。 | 微服务、容器或无服务器函数。 |
| 数据存储 | 本地数据库。 | 云存储、分布式缓存或分片数据库。 |
| 边界 | 系统边界。 | 网络边界、信任区域或API网关。 |
在绘制不同节点中进程之间的数据流时,用传输机制(例如HTTPS、gRPC、消息队列)对流进行注释会很有帮助。这为性能和安全要求提供了上下文。
🛡️ 处理并发与状态
分布式系统经常处理并发请求。静态的DFD可能不会明确显示时间,但它必须暗示在这些交互过程中状态是如何管理的。⏳
- 无状态进程:如果一个进程不存储状态,DFD应显示数据流经并退出,而不会为该特定事务返回到存储中。
- 有状态进程:如果一个进程维护状态,则必须有明确的数据流指向一个持久化该信息的数据存储。
- 一致性:表示更新的数据流必须说明如何在节点之间保持一致性。
例如,在建模购物车时,DFD应显示“购物车数据”从用户实体流向购物车服务,再流向数据库存储。如果购物车服务是分布式的,该流应表明哪个节点持有数据的权威副本。
🚫 分布式建模中的常见陷阱
即使是经验丰富的架构师在可视化分布式数据流时也可能出错。意识到这些常见错误有助于提高模型的质量。 🚧
| 陷阱 | 影响 | 纠正 |
|---|---|---|
| 黑洞流程 | 数据进入流程,但从未离开。 | 确保每个输入都有相应的输出或存储。 |
| 灰洞流程 | 输出存在,但没有输入能解释它们。 | 验证每个输出流的所有数据源。 |
| 蜘蛛网 | 交叉线条过多,造成混淆。 | 使用子流程来分组相关数据流。 |
| 忽视网络因素 | 忽视延迟或故障点。 | 用协议和可靠性备注标注数据流。 |
避免在数据存储之间直接连线而不经过流程。数据存储只能通过验证和转换数据的流程进行交互。这可以防止未经授权的直接访问,并确保业务逻辑得到应用。
📝 清晰性最佳实践
创建一个既准确又易读的图表,需要遵循特定的设计原则。 🎨
- 命名一致:在所有图表中对同一数据使用相同的术语。如果在 Level 0 中使用“用户ID”,则在 Level 1 中不应称为“客户键”。
- 逻辑分组:在视觉上将相关流程分组。这有助于识别服务边界。
- 限制扇出:避免一个流程连接超过十个数据流。如果发生这种情况,应分解该流程。
- 颜色编码:使用颜色区分内部流程、外部实体和数据存储。这有助于快速浏览。
- 版本控制:将图表视为代码。将其存储在版本控制系统中,以跟踪随时间的变化。
在为分布式系统建模时,可考虑使用泳道来表示不同的信任区域或网络段。这能立即明确哪些组件是面向公众的,哪些是内部的。
🔒 集成安全考量
安全不是事后考虑的问题;它必须与功能设计并行建模。🔐 数据流图提供了一个独特的机会,可以在设计阶段早期识别安全风险。
- 认证点:标记用户凭据被验证的位置。这通常发生在外部实体与第一个处理过程之间的边界处。
- 数据加密:标明敏感数据流被加密的位置。在箭头上使用“加密通道”等标签。
- 访问控制:展示哪些处理过程有权访问特定的数据存储。
- 日志记录:包含将审计日志发送到独立日志存储的流程。这确保了可追溯性。
通过显式建模这些安全流程,团队可以确保在实施过程中不会遗漏加密和认证。这促使团队就数据隐私和合规要求展开讨论。
🔄 维护与演进
系统会不断演进。需求会变化,新服务也会被添加。数据流图是一个活文档,必须持续维护才能保持其价值。🔄
- 定期审查:安排开发团队定期审查数据流图,以确保它们与当前代码库一致。
- 变更管理:新增功能时,应立即更新图表,不要等到下一个文档迭代周期。
- 依赖关系追踪:使用图表来追踪依赖关系。如果移除一个数据存储,数据流图将突出显示哪些流程会受到影响。
不符合现实的文档会带来技术债务。保持数据流图的更新可以缩短新工程师的入职时间,并防止架构漂移。
🛠️ 实施策略
你实际上该如何开始建模一个复杂系统?遵循结构化的方法以确保完整性。📋
- 识别实体:列出与系统交互的所有用户、外部系统和设备。
- 定义边界:清晰地画出系统边界线。边界内部是系统本身,外部则是外部实体。
- 绘制高层流程:首先绘制上下文图。确保所有输入和输出都已涵盖。
- 分解流程:将主流程分解为子流程。用动词为它们命名。
- 添加数据存储: 确定数据需要持久化的位置。将其与相关流程连接起来。
- 验证: 检查是否存在黑洞和灰洞。确保每个数据流都有明确的源和目标。
- 优化: 为分布式环境添加关于协议、加密和网络边界的详细信息。
这个迭代过程确保在编写代码之前模型是稳健的。通过早期发现逻辑错误,节省了时间。
🚀 结论
数据流图是设计分布式系统的基础工具。它们提供了必要的清晰度,以理解数据如何在复杂网络中流动。通过遵循最佳实践,避免常见陷阱,并持续维护这些图表,团队可以构建可扩展、安全且可靠的系统。🌟
建模所投入的努力在开发和维护阶段都会带来回报。清晰的图表有助于开发人员、利益相关者和运维团队之间的更好沟通。它们是系统架构的唯一真实来源。
从今天开始绘制您的分布式系统。专注于清晰性、一致性和准确性。当架构需要扩展或新成员入职时,未来的你会感谢现在的自己。🏁